
Introduction
Modern data platform serves as a fundamental unit while building a data-driven organization.
These cloud-native and cloud-first frameworks also help in a quicker and easier setup.
Their prominent characteristics include the ability to make precise business decisions, flexibility, and agile data management. Moreover, the intuitive nature allows for simple business decision-making with very few clicks. Also, they operate on two common principles, namely, scalability and availability. Data is readily available in data lakes or warehouses – There is a clear distinction between storage and computation ability, thereby allowing for massive storage at a convenient cost. The auto-scalability feature allows the end-user to consume data the most when necessary.
Essentially, a modern data platform has the following eight components, including data ingestion, warehouse, lakehouse, business intelligence, data transformation, data science, governance, and privacy.
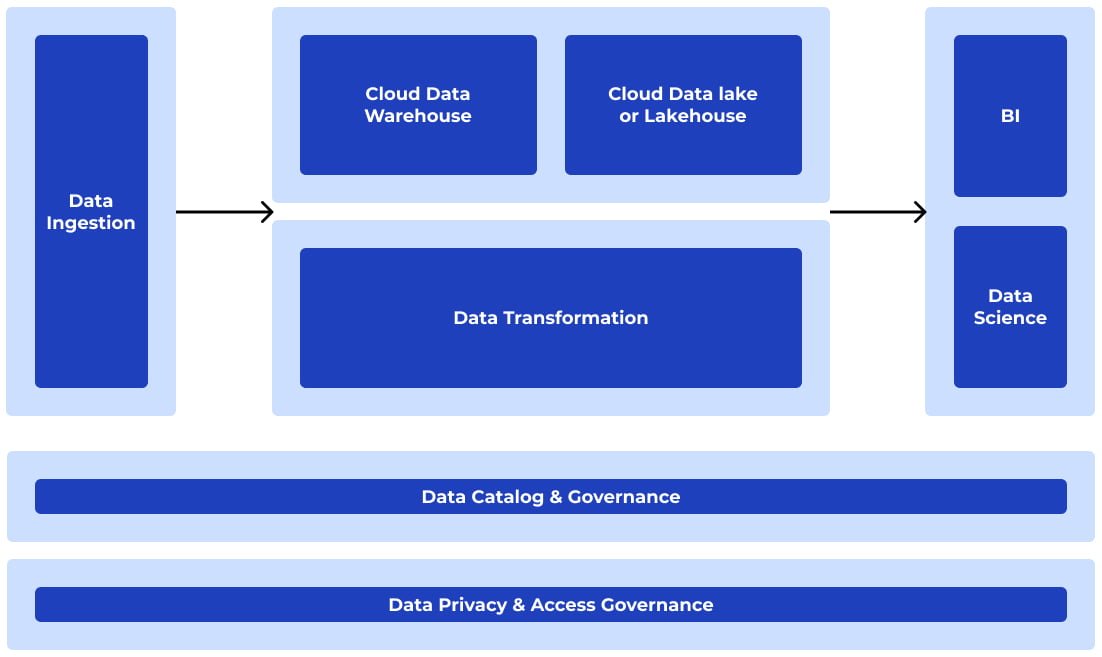
What’s the ROI of having it?
The return on investment of having a great data platform is nothing but the ROI of having high-quality or impactful data at the most significant times. The real value lies in its capacity to detect and capacity to be fixed. The ability to identify is the time it takes to find an outlier using advanced machine learning algorithms or approaches. And the second metric can be defined as the ability or the time taken to control or fix an anomaly. Often, the first metric impacts the second metric.
Further, building good data pipelines depends on various characteristics, such as the architecture and the mechanisms for monitoring or handling failures. Some proven methods are having short-run jobs, allocating separate clusters for data pipelines, and tracking metrics.
Popular ML techniques for achieving robust data quality
Deep learning and advanced techniques help in achieving improved performance and increased accuracy. Today, data is growing exponentially at a rate that can’t be presumed before. However, to realize the exact value, data has to be transformed to its high-quality state.

Let’s deep dive into seven vital strategies for getting superior data quality:
- Automated data entry: Entering data manually into several systems doesn’t serve as an optimum solution. With growing unstructured data, technologies like OCR, speech-to-text are in great demand.
- Manage data quality at the source: Advanced algorithms help normalize data – Supervised machine learning solutions also provide an opportunity to rectify errors with the help of reference data. We could find the relevant match across records or sources and predict accordingly using record linkages.
- Fill data gaps: Correlation within historical data could be used to find or predict the missing values. And as time passes, the algorithms could also learn and become more accurate. In the absence of historical information, expectation-maximization algorithms could be utilized. These methods give maximum likelihood estimates and feedback could be used to build accuracy over time.
- Handle incorrect reporting: Regulatory reporting is a cumbersome process. Besides, existing methods always include lengthy and strenuous manual routines. Techniques like the Logit model and Random Forest helps in drastically improving the quality of reporting.
- Create business rules: Algorithms like decision trees can be used in building a robust rule engine framework. The process involves using the existing business rule engine as a reference and building on that framework.
- Manage reconciliation: You can use ML techniques like Fuzzy logic to resolve reconciliation issues effectively. Some additional methods include using historical data, user actions, and exceptions management.
- Monitor SLAs: We use methods like regression and classification to better adhere to SLAs. Common practices include setting SLAs to govern the acquisition of source data and supply of aggregated data to consumers.
Best practices for managing data downtime
While embarking on the path to becoming a data-driven organization, companies develop strategies for realizing maximum data uptime and managing data downtime proactively. Usually, they use a standard like reliability maturity curve in the process. The graph has four stages, including reactive, proactive, automated, and scalable state.
Conclusion
Thus, a modern data platform adopts the cloud and encompasses self-service features. It performs well on four pillars, including operational excellence, security, reliability, performance & cost optimization. We’ve also seen how to achieve robust data quality through advanced computational techniques and how diligently managing data downtime helps a long way.
Here’s a glimpse into how AI helps you make better business decisions.