
With ever-increasing demands on businesses and organizations, managing heavy workloads is becoming more and more difficult. Fortunately, with the advent of cloud computing, companies can now leverage the power of Amazon Web Services (AWS), Elastic MapReduce (EMR), and Apache Spark to manage large workloads far easier. AWS EMR and Spark provide robust and reliable data processing capabilities, enabling businesses to quickly and easily scale their workloads horizontally to meet the demands of their customers. With these tools, companies can efficiently manage their heavy workloads and drive growth without sacrificing performance or reliability. With AWS EMR and Spark, businesses can now unlock the potential of their data and stay on top of their ever-growing workloads.
Do you need to scale up your data processing capabilities quickly? Are you looking for the most cost-effective way to run large workloads? If so, then AWS EMR and Spark are what you need. This blog post will look at how these two powerful tools can help you run heavy workloads efficiently.
Introduction to Apache Spark
Image Credits: Databricks
Apache Spark is an open-source, large-scale data processing engine used for big data analytics and machine learning. It is designed to provide high-level APIs in Scala, Java, Python, and R and supports SQL, streaming, and graph processing. Spark is built on top of the Hadoop Distributed File System (HDFS) and provides an alternative to the traditional MapReduce programming model. It provides an in-memory data processing capability, allowing faster processing than traditional disk-based systems. Spark’s ability to cache data in memory and its ability to run multiple parallel processing tasks make it ideal for use cases where quick iterative processing and real-time data processing are required. Spark has a large and growing community of users, and organizations across various industries for big data processing and analysis widely use it.
Introduction to AWS EMR
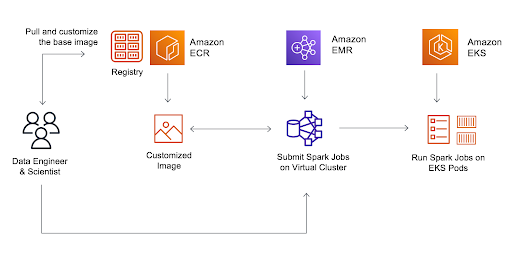
Image Credits: AWS
AWS EMR (Amazon Web Services Elastic MapReduce) is a fully managed, cloud-based big data processing and analysis platform. It is designed to make it easy for users to run big data processing and analytics workflows without worrying about the underlying infrastructure. EMR provides a managed Hadoop framework that automatically provisions and configures the necessary hardware and software components to process large amounts of data. This includes popular big data processing engines like Apache Spark, Apache Hive, Apache Hadoop, and Apache Pig. With EMR, users can process and analyze vast amounts of data in a matter of minutes, and the platform integrates seamlessly with other AWS services like S3, RDS, and Kinesis. By using EMR, organizations can quickly and cost-effectively process big data, extract insights and make data-driven decisions.
Benefits of Apache Spark
There are several benefits to using AWS EMR and Apache Spark for managing heavy workloads.
- First, they make it easier for businesses to process and analyze large amounts of data quickly and efficiently. By using AWS EMR and Apache Spark, businesses can quickly scale their workloads horizontally to meet the demands of their customers without sacrificing performance or reliability. Additionally, with AWS EMR and Apache Spark, businesses can more easily integrate with other tools and services, such as Amazon S3 and Amazon Kinesis, to further enhance their data processing capabilities.
- When used together, AWS EMR and Apache Spark can provide organizations with the tools they need to process large volumes of data efficiently. By leveraging the advantages of both platforms, organizations can save time and money and increase efficiency. AWS EMR and Apache Spark can help organizations make the most of their data and drive business growth.
- One of the major benefits of using AWS EMR and Apache Spark for heavy workloads is its scalability. With AWS EMR and Apache Spark, businesses can scale up or down depending on their needs. This allows businesses to reduce their costs while at the same time increasing their efficiency. AWS EMR and Apache Spark also provide fault tolerance, meaning that if one node fails, the system can continue running without any interruption. This is a huge advantage for workloads requiring a high-reliability level.
- AWS EMR and Apache Spark are also known for their high performance. They can process large amounts of data quickly and efficiently. This helps businesses make decisions and take action faster than ever before. AWS EMR and Apache Spark also provide a wide range of data analysis and visualization tools. This makes it easy for businesses to get insights from their data and make better decisions.
- AWS EMR and Apache Spark are also secure and reliable. AWS offers a wide range of security features to ensure data security. This includes encryption at rest and in transit, authentication, and access control. Additionally, AWS EMR and Apache Spark are designed to handle large amounts of data without downtime or performance issues. This makes them ideal for handling large workloads.
- Overall, AWS EMR and Apache Spark offer businesses a lot of benefits. They are scalable, secure, reliable, and high-performance solutions that can handle large workloads. This makes them a great choice for businesses that need to process large amounts of data quickly and securely. AWS EMR and Apache Spark can help businesses save time and money while ensuring their data is secure.
Best Practices for Using AWS EMR and Apache Spark
Using AWS EMR and Apache Spark is fairly straightforward. To start, businesses must set up an AWS EMR cluster. This involves launching a cluster of EC2 instances and configuring them to run the EMR software. Once the cluster is up and running, businesses can then configure their Apache Spark jobs and begin processing and analyzing data.
- First, it’s important to choose the right instance type and size for your cluster based on the size and complexity of your data. Additionally, it’s recommended to enable automatic scaling to adjust the number of nodes in your cluster based on workload demands. To optimize performance, it’s important to tune your Spark configuration and use efficient data formats. It’s also important to use spot instances to save costs, but be sure to manage job failures appropriately.
- Finally, it’s crucial to properly secure your cluster, which can be done by using security groups, encryption, and access control policies. By following these best practices, you can ensure that your EMR and Spark deployments are scalable, performant, and secure.
When using AWS EMR and Apache Spark, it is important to follow best practices to ensure optimal performance and reliability:
- The first best practice is to use the right version of Spark for your use case. Different versions of Spark have different capabilities and features. Therefore, it is important to select the right version of Spark based on your use case.
- The second best practice is to use the right instance type when setting up an EMR cluster. Different instance types are optimized for different workloads. Therefore, it is important to select the right instance type based on your requirements.
- The third best practice is to use the right storage option. AWS EMR supports different storage options such as EBS and S3. Depending on the use case, it is important to select the right storage option. For example, if the data needs to be accessed frequently, it is better to use EBS.
- The fourth best practice is to use Spot Instances. Spot Instances can help reduce the cost of running an EMR cluster. Therefore, it is important to take advantage of Spot Instances when setting up an EMR cluster.
- The fifth best practice is to use the right configuration settings. Different configuration settings can have a significant impact on the performance of the cluster. Therefore, it is important to select the right configuration settings for the cluster.
By following these best practices for using AWS EMR and Apache Spark, data engineers and data scientists can get the most out of these powerful tools. Both AWS EMR and Apache Spark are powerful tools that can help organizations get insights from their data and make better decisions.
AWS EMR & Apache Spark: Better Together
These are the two powerful technologies that are better together. EMR is a managed Hadoop framework that allows users to easily deploy and manage big data processing jobs. Apache Spark is an open-source data processing engine that can perform batch processing, stream processing, and machine learning tasks on large datasets. EMR and Spark offer a powerful and flexible solution for big data processing that can scale easily based on workload demands. EMR simplifies the deployment and management of Spark, allowing users to focus on data processing and analysis. Spark can take advantage of EMR’s auto-scaling features to adjust resources based on demand, ensuring efficient use of resources and reducing costs. Additionally, EMR and Spark integrate with other AWS services, such as Amazon S3 and Amazon DynamoDB, making it easy to ingest, store, and process data from a variety of sources. EMR and Spark provide a powerful combination of big data processing tools that can help organizations gain insights and make informed decisions.
Setting up an AWS EMR Cluster
Setting up an AWS EMR cluster is relatively simple. First, businesses will need to launch a cluster of EC2 instances. This can be done via the AWS Management Console or using the AWS Command Line Interface (CLI). Once the cluster is launched, businesses will then need to configure the instances to run the EMR software. This can be done using the AWS EMR console or using the AWS CLI.
Under EMR on EC2, choose Clusters in the left navigation pane, and then choose Create cluster. On the Create Cluster page, note the default values for Release, Master Instance Type, Core Instance Type, Number of Instances, and Storage Capacity. You can then customize your cluster according to your specific needs. Once your cluster is set up and running, you can launch Spark executor pods on EC2 Spot Instances to take advantage of lower pricing for EC2 instance types. Additionally, you can use Amazon EMR on EKS to run Spark workloads for further computing power and scalability.
Benefits of Running Spark on AWS EMR
Running Spark on AWS EMR offers numerous advantages. It makes managing and scaling Spark workloads easier and provides better performance and cost savings. Amazon EMR provides an optimized runtime for Apache Spark that can help improve performance by up to 3.5 times compared to other solutions. This performance gain helps reduce compute costs without needing application changes. Additionally, AWS EMR allows you to run and debug Spark applications on AWS with Amazon EKS, schedule Spark executor pods on EC2 Spot Instances, and integrate Amazon EMR with other AWS services. This makes running heavy workloads with Spark much more efficient and cost-effective.
Running Complex Workloads with AWS EMR
Amazon EMR helps customers run complex workloads with Apache Spark, enabling them to utilize AWS scalability and cost savings. Customers configure their EMR cluster easily, employing managed scaling with minimum and maximum capacity, core, and task nodes. Amazon EMR also facilitates workload execution on EC2 instances, Amazon EKS clusters, and on-premises using EMR on AWS Outposts. Cost savings are achieved by scheduling Spark executor pods on EC2 Spot Instances for heavy workloads. Additionally, Amazon EMR Runtime for Apache Spark enhances performance by pre-warming executors before requests. Amazon EMR integrates with AWS Lambda and Amazon SageMaker for advanced analytics and machine learning. Leveraging Amazon EMR capabilities, customers can efficiently manage complex workloads at scale while reducing costs and improving performance.
Using EMR on EKS for Spark Workloads
Amazon EMR on EKS provides an affordable and reliable option for running Apache Spark workloads. It helps run Spark workloads faster, leading to lower running costs. In addition, by using Amazon EMR on EKS, users can submit Spark jobs on demand without having to provision clusters. This makes it easy to manage and scale your workloads with minimal effort. Moreover, Amazon EMR on EKS can be further optimized to reduce costs by scheduling executor pods on EC2 Spot Instances. Furthermore, Amazon EMR Runtime for Apache Spark allows for improved performance and can help run complex workloads efficiently. Finally, Amazon EMR integrates with other AWS services to provide a comprehensive solution for data processing and analytics needs.
Scaling Your Workloads with AWS EMR and Apache Spark
AWS EMR and Apache Spark enable businesses to rapidly scale workloads horizontally to meet customer demands. With AWS EMR and Apache Spark, businesses can flexibly spin up and down clusters as required, ensuring optimal workload performance. Leveraging Amazon’s cloud, businesses can scale workloads quickly without compromising performance or reliability.
EMR provides support for both horizontal scaling, where you can add more nodes to the cluster to increase processing power, and vertical scaling, where you can use larger EC2 instances with more memory and CPU resources.
To scale your Apache Spark workloads on EMR, you can take advantage of the following features:
- Auto Scaling: EMR supports automatic scaling, where the cluster can automatically add or remove nodes based on the workload demand.
- Spot Instances: You can use EC2 Spot Instances to save money on your cluster costs while still having the ability to run your Apache Spark workloads.
- EC2 Instance Types: EMR provides support for a variety of EC2 instance types, ranging from small, low-cost instances to large, high-performance instances with large amounts of memory and CPU resources.
- Custom AMIs: You can create custom Amazon Machine Images (AMIs) with pre-installed software and configurations, allowing you to quickly spin up new EMR clusters with the necessary tools and configurations.
By taking advantage of these features, you can easily scale your Apache Spark workloads on AWS EMR to meet your processing needs and optimize your costs. Additionally, by using a managed platform like EMR, you can simplify the process of setting up and managing your big data clusters, freeing up time and resources to focus on your data processing and analysis tasks.
How Digital Alpha Can Help Scale Your Heavy Workloads?
Digital Alpha can help companies run heavy workloads with AWS EMR and Apache Spark by providing expert guidance and support in the following areas:
Digital Alpha can help you optimize your EMR cluster to ensure it is properly configured to handle your Apache Spark workloads. This may include choosing the right EC2 instances, tuning the Spark configuration, and optimizing network settings for maximum performance. Digital Alpha can help you manage your data storage on AWS, including setting up data storage and retrieval with Amazon S3 and integrating with other data sources like Amazon Redshift or RDS. Digital Alpha can help you automate your Apache Spark workloads, including scheduling jobs, managing dependencies, and monitoring the cluster for performance and errors.
By working with Digital Alpha, companies can leverage the power of AWS EMR and Apache Spark to process large amounts of data and perform complex data processing and analysis tasks. With expert guidance and support, companies can optimize their cluster configurations, manage their data effectively, and automate their Apache Spark workloads to save time and resources.
AWS EMR and Apache Spark provide businesses with powerful and reliable data processing capabilities, enabling them to quickly and easily manage their heavy workloads. With AWS EMR and Apache Spark, businesses can easily scale their workloads horizontally to meet their customers’ demands while also leveraging machine learning’s power to uncover insights from their data. Additionally, businesses can integrate AWS EMR and Apache Spark with other tools and services to further enhance their data processing capabilities. With AWS EMR and Apache Spark, businesses can now unlock the potential of their data and stay on top of their ever-growing workloads.