
As we progress digitally, data generation and consumption surge. Efficient data management systems become imperative to handle vast data variety. Modern platforms rely on open-source tech for evolution.
Introduction to Modern Data Platforms
Modern data platforms are designed to manage and process large volumes of data from various sources in real time. These platforms are used to build data-driven applications and provide insights for decision-making. They typically include a range of tools and technologies such as databases, data lakes, data warehouses, and data pipelines. The primary goal of modern data platforms is to enable businesses to collect, store, process, and analyze data at scale. This data can come from multiple sources, such as web applications, mobile apps, IoT devices, and social media platforms. By leveraging modern data platforms, businesses can gain a competitive advantage. Businesses make data-driven decisions, improve customer experiences, and optimize business processes by utilizing data-driven strategies.
The Evolution of Data Management
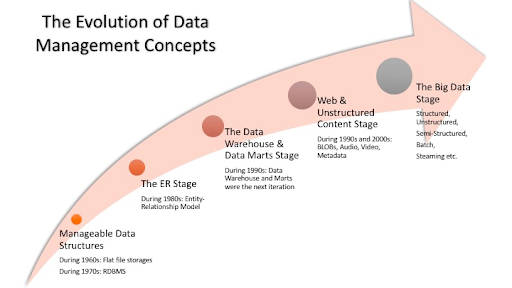
Image Credits: Contemplating Data
The evolution of data management traces back to the early days of computing when people stored data on physical media such as punch cards and magnetic tapes. As technology progressed, developers created databases to store and manage data electronically. Initially, specific vendors built and maintained these proprietary databases, which required licensing fees to use. Over time, open-source databases such as MySQL and PostgreSQL were developed, providing an alternative to proprietary databases. Open-source databases are free to use, modify, and distribute, making them more accessible to a wider range of users. This led to the development of open-source data platforms that are now widely used in modern data management.
The Role of Open Source in Modern Data Platforms
Open-source technology has revolutionized the world of modern data platforms. It has transformed the way organizations manage and analyze data, providing a powerful, flexible, and cost-effective solution for businesses of all sizes. In this essay, we will explore the role of open source in modern data platforms, examining its impact on data management, analytics, and machine learning. Open-source data platforms provide organizations with the ability to manage and store large volumes of data in a cost-effective manner. They offer a range of tools and technologies that enable businesses to capture, process, and analyze data at scale. Developers build these platforms on open-source software, making them freely available and customizable to meet the specific needs of an organization. This flexibility allows businesses to develop data solutions tailored to their specific requirements, giving them a competitive edge.
One of the key benefits of open-source data platforms is the ability to integrate multiple data sources. With the rise of big data, organizations are increasingly using a variety of data sources to gain insights into their business operations. Open-source data platforms provide the ability to combine structured and unstructured data from a range of sources, including social media, customer feedback, and IoT devices. This integration enables businesses to gain a holistic view of their operations, allowing them to make better-informed decisions.
Open-source technology has also had a significant impact on data analytics. These platforms provide businesses with powerful tools for data exploration and visualization, enabling them to identify trends and patterns in their data. You can apply machine learning algorithms to the data to identify correlations, make predictions, and generate insights that inform decision-making. With open-source data platforms, businesses can develop their analytics capabilities quickly and cost-effectively without the need for extensive IT resources.
Finally, open-source technology has transformed the way organizations approach machine learning. With the rise of AI and machine learning, businesses are increasingly using these technologies to gain a competitive advantage.
Examples of Open Source Data Platforms
Open-source technology is also more secure and reliable than proprietary technology. The open-source community is constantly working to identify and patch security vulnerabilities, making open-source software more secure than proprietary software. Additionally, open-source technology is typically more stable and reliable as it is tested and used by a large community of users.
There are several examples of open-source data platforms that are widely used in modern data management.

- Apache Hadoop: An open-source software framework that is used for distributed storage and processing of big data.
- Apache Cassandra: A distributed NoSQL database management system that can handle large amounts of data across multiple servers.
- Apache Spark: A fast and general-purpose cluster computing system that is used for large-scale data processing.
- MongoDB: A document-oriented NoSQL database management system that provides high availability and scalability.
- PostgreSQL: An open-source relational database management system that is known for its reliability, security, and performance.
- Elasticsearch: A distributed search and analytics engine that can be used for various use cases, such as logging, monitoring, and full-text search.
- Apache Flink: A distributed stream processing engine that is used for real-time data processing.
- Apache Beam: A unified programming model that is used for batch and stream processing of data.
- Apache Kafka: A distributed streaming platform that is used for building real-time data pipelines and streaming applications.
- InfluxDB: A time series database that is used for storing and querying time-stamped data.
How Open Source is Driving Innovation in Data Management
Open source software has played a significant role in driving innovation in the field of data management. With the rise of big data and the increasing need for businesses to manage and analyze large amounts of data, open source software has become an essential tool for companies of all sizes. Open source data management tools are now widely used in various industries, including finance, healthcare, and education, to name a few.
One of the primary advantages of open source data management software is its flexibility. Open source tools can be easily customized to meet the specific needs of a business, allowing companies to create tailored solutions that are perfectly suited to their unique data management requirements. Additionally, open-source software is often more cost-effective than proprietary solutions, making it an attractive option for companies with limited budgets.
Another benefit of open-source software is the collaborative nature of the development process. Open source projects are typically community-driven, with developers and users from around the world working together to improve the software. This collaborative approach to software development accelerates the pace of innovation, as developers continually share and implement new ideas and improvements.
Open-source data management tools also offer greater transparency than proprietary solutions. With open-source software, users have access to the source code, which means they can review and modify the software to ensure it meets their specific needs. This level of transparency additionally promotes security, as developers can identify and address vulnerabilities more quickly than with proprietary software. Finally, open-source software is often more interoperable than proprietary solutions. Developers design many open-source data management tools to work seamlessly with other open-source tools, enabling companies to create integrated solutions that leverage the strengths of multiple tools.
Modern Data Stack with Airbyte, Airflow, dbt, and Spark in AWS

In today’s digital age, businesses generate and collect more data than ever. However, the sheer amount of data can be overwhelming and challenging to manage, leading to inefficiencies and missed opportunities. That’s where a modern data stack comes in, utilizing a combination of tools and technologies to manage and utilize large amounts of data effectively. In this article, we’ll explore the use of Airbyte, Airflow, dbt, and Spark in an AWS environment to create a modern data stack.
Airbyte is an open-source data integration platform that enables businesses to extract data from various sources, transform it, and load it into a target destination. Airbyte connects to over 200 sources, including databases, APIs, and SaaS platforms, making it easy to integrate data from a variety of sources. It also supports both batch and real-time data integration, providing flexibility for different use cases.
Airflow is an open-source platform for workflow management that allows businesses to schedule and orchestrate data processing tasks. It enables users to define, schedule, and monitor workflows, making managing and automating data processing tasks easier. It can also integrate with a variety of tools, making it a flexible solution for different use cases.
dbt or data build tool, is an open-source command-line tool that transforms raw data into analytics-ready tables. dbt simplifies the process of transforming data by providing a framework for writing and testing SQL scripts. This makes it easier for businesses to maintain their data pipelines and ensure data accuracy.
Spark is an open-source big data processing engine that can handle large-scale data processing. Businesses often use it for data transformation, analysis, and machine learning. Its high scalability enables businesses to process large volumes of data quickly and efficiently. Together, these tools help create a modern data stack in an AWS environment. Airbyte extracts data from various sources and loads it into AWS S3 buckets. Airflow schedules and orchestrates the data processing tasks, utilizing dbt to transform raw data into analytics-ready tables. Finally, Spark performs large-scale data processing and analysis.
Integrating Airbyte, Airflow, Dbt, and Spark in AWS
To integrate Airbyte, Airflow, Dbt, and Spark in AWS, you will need to do the following:
- Configure Airbyte to extract data from different data sources.
- Configure Airflow to create workflows that automate data processing tasks.
- Configure Dbt to transform raw data into structured data that is easy to analyze.
- Configure Spark to process large amounts of data quickly.
Once you have integrated these tools, you will have a modern data stack that can handle the processing and analysis of large amounts of data.
Using a modern data stack can provide numerous benefits for businesses, including increased efficiency, scalability, and agility. By utilizing open-source tools such as Airbyte, Airflow, dbt, and Spark in an AWS environment, businesses can effectively manage and utilize large amounts of data, making better-informed decisions and driving growth.
Conclusion
In conclusion, open-source technology is revolutionizing data management, and developers are now building modern data platforms using open-source solutions. With the increasing amount of data generated every day, organizations are seeking better ways to manage, store, process, and analyze their data. Open-source technology provides a cost-effective, flexible, and scalable solution that enables organizations to leverage the power of data to drive business growth and innovation. By leveraging open-source data management solutions, organizations can reduce costs, improve data quality, accelerate time to market, and make data-driven decisions with confidence. The future of data management belongs to open-source technology, and organizations that embrace this trend will have a significant competitive advantage in today’s digital economy.
Digital Alpha can help you with modern data challenges in several ways, starting with data strategy and governance, ensuring data quality, accuracy, and security. Data management and integration, advanced analytics, cloud migration, and management. Overall, Digital Alpha helps you tackle modern data challenges by providing end-to-end data management solutions tailored to your specific needs and objectives.
Digital Alpha offers data management solutions on AWS Marketplace, a digital catalog of software and services easily accessible to AWS customers.On the AWS Marketplace, Digital Alpha provides a range of data management solutions, such as running heavy data and analytics workloads, data discovery tools to uncover new insights, and much more.
To learn more about how open-source technology can revolutionize your data management, contact us today. Our team of experts can help you navigate the complex world of open-source data platforms and provide you with the tools and technologies you need to succeed.