
Background
Every investor who has invested or considered investing in risky assets at some point has thought about the most they can lose on the investment. Value at Risk (VAR) provides some answers to this with a certain probability. VAR is one of the quantitative methods used to estimate the largest loss that can occur with a prescribed probability in the future. Investors make investment decisions based on three criteria: return, risk, and liquidity. Analysts have to deal with vast volumes of data for risk evaluation and assessment to optimize the portfolio. According to Statista, the mass volume of data created, stored, copied, and consumed in 2020 was over 64 zettabytes (ZB), or about 64 trillion gigabytes (GB). This is expected to rise to 181 ZB by the year 2025.
Challenge
The firm heavily invests in data collection and processing of complex data sets to make investment decisions. Analysis and prediction of this data require them to create data lakes using multiple open-source tools like apache spark, hudi, etc., and massive computational power. Although popular in financial services, VAR comes with certain challenges and limitations for its calculation and implementation:
- For businesses to set up an EMR infrastructure, they need to install all the required hardware and provide network connectivity with each of them.
- The cost of maintaining the infrastructure is high. Organizations need dedicated resources who can work as big data analysts or have knowledge of setting up EMR-Spark clusters.
- Resources get wasted because not every day organizations need this high computation power.
Digital Alpha brings in its data platform using Amazon EMR for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications.
Solution
The goal is to implement a CI/CD solution that automates the provisioning of EMR cluster resources and performs ETL jobs directly. The EMR solution was built through CDK, Step Functions Workflow, and AWS Lambda.
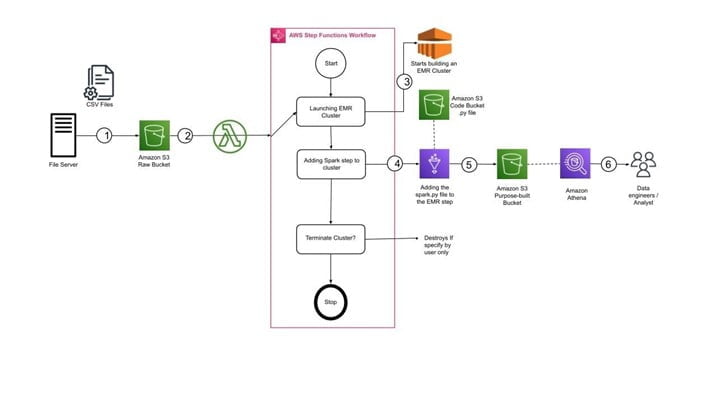
An input bucket is created where developers can update the raw input data in CSV format. The file modification will trigger the lambda function, which creates a new EMR cluster. Step Functions initiate the execution of EMR clusters.
Within the EMR cluster, an auto-scaling policy has been used to increase the instances as the workload increases.
ML instances and on-demand instances are used that can be configured by default.
These clusters are launched with pre-configured security groups, so it doesn’t require manually updating the inbound-outbound rules.
A workflow is built that gets triggered as soon as a file arrives in S3, and the objective of the workflow is to execute a Spark + Hudi job to process the input file. The workflow is supposed to create a transient EMR cluster, submit a Spark job that does ETL transforms, and then terminate the cluster upon completion.
Benefits
- Amazon EMR pricing depends on the instance type, the number of Amazon EC2 instances deployed, and the Region in which the cluster is launched. On-demand pricing offers low rates, but the cost can be reduced further by purchasing Reserved Instances or Spot Instances. Spot Instances can provide significant savings—as low as a tenth of on-demand pricing in some cases.
- Amazon EMR integrates with other AWS services to provide capabilities and functionality related to networking, storage, and security for a cluster. The following list provides several examples of this integration:- Amazon EC2 for the instances that comprise the nodes in the cluster
– Amazon Virtual Private Cloud (Amazon VPC) to configure the virtual network in which you launch your instance
– Amazon S3 to store input and output data
– Amazon CloudWatch to monitor cluster performance and configure alarms
– AWS Identity and Access Management (IAM) to configure permissions
– AWS CloudTrail to audit requests made to the service
– AWS Data Pipeline to schedule and start the clusters
– AWS Lake Formation to discover, catalog, and secure data in an Amazon S3 data lake
– Amazon EMR provides flexibility to scale the cluster up or down as the computing needs change. The cluster can be resized to add instances for peak workloads and remove instances to control costs when peak workloads subside.
– Amazon EMR monitors nodes in the cluster and automatically terminates and replaces an instance in case of failure.
– Amazon EMR provides configuration options that control if a cluster is terminated automatically or manually. If a cluster is configured to be automatically terminated, it is terminated after all the steps are complete. This is referred to as a transient cluster.