
Background
Organizations can use Document Understanding Solution to digitize and store customer feedback and request forms, and a finance department can convert invoices and balance sheets into consumable CSV files. Hospitals can use this solution to extract medical entities, for example, medical conditions, medications, and protected health information (PHI) from documents. A law firm can redact dates and references to people and locations from a document before sharing it with external parties using the redaction controls. Document understanding provides the means to store, index, query, and analyze entire categories of documents where these operations were previously impossible (or at least hugely expensive and impractical).
Challenge
Manual contract review is risky. When a legal team completes its work, its findings might not even be relevant anymore. And that’s before considering the possibility of key contracts and details slipping through the cracks due to misclassification or difficulties with search. Critical activities such as due diligence get slowed down due to these issues. Intelligent document processing and classification give the next level of visibility to analyze legal documents, identify and get insights from them in seconds, dramatically reducing contract review time. This leads to better risk management, faster due diligence, and tremendous efficiency gains. Information retrieval, however, is complex, incurs a high cost, and requires extensive manual efforts.
Solution
Document understanding automates much of the review process. It does the heavy lifting of extracting data from text and presenting it intuitive, user-friendly way. Accordingly, due diligence can proceed more quickly, and risks are often identified early.
The Document Understanding Solution (DUS) delivers an easy-to-use web application that ingests and analyzes files, extracts text from documents, identifies structural data (tables, key-value pairs), extracts critical information (entities), and creates smart search indexes from the data.
Additionally, files can be uploaded directly to, and analyzed files can be accessed from an Amazon Simple Storage Service (Amazon S3) bucket in the AWS account. DUS leverages multiple ML services, including Amazon Textract. Amazon Textract is a fully managed machine learning service that automatically extracts text and data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. Amazon Textract moves the data from the documents to a format that can be readily searched.
Next, Amazon Kendra and Amazon OpenSearch Service provide the end user search experience in DUS. Amazon Kendra is an intelligent search service powered by machine learning. Amazon Kendra uses ML to obtain better results for natural language questions and returns an exact answer from within the document, whether a text snippet, FAQ, or PDF document. In addition to Amazon Kendra, the DUS provides a rich search experience to the user through the Amazon Opensearch Service. Amazon OpenSearch Service is a fully managed service that makes it easy to deploy, secure, and run Elasticsearch cost-effectively at scale. This solution uses AWS artificial intelligence (AI) services that address business problems that apply to various industry verticals:
- Search and discovery: Search for information across multiple scanned documents, PDFs, and images.
- Compliance: Redact information from documents
- Workflow automation: Easily plugs into your existing upstream and downstream applications
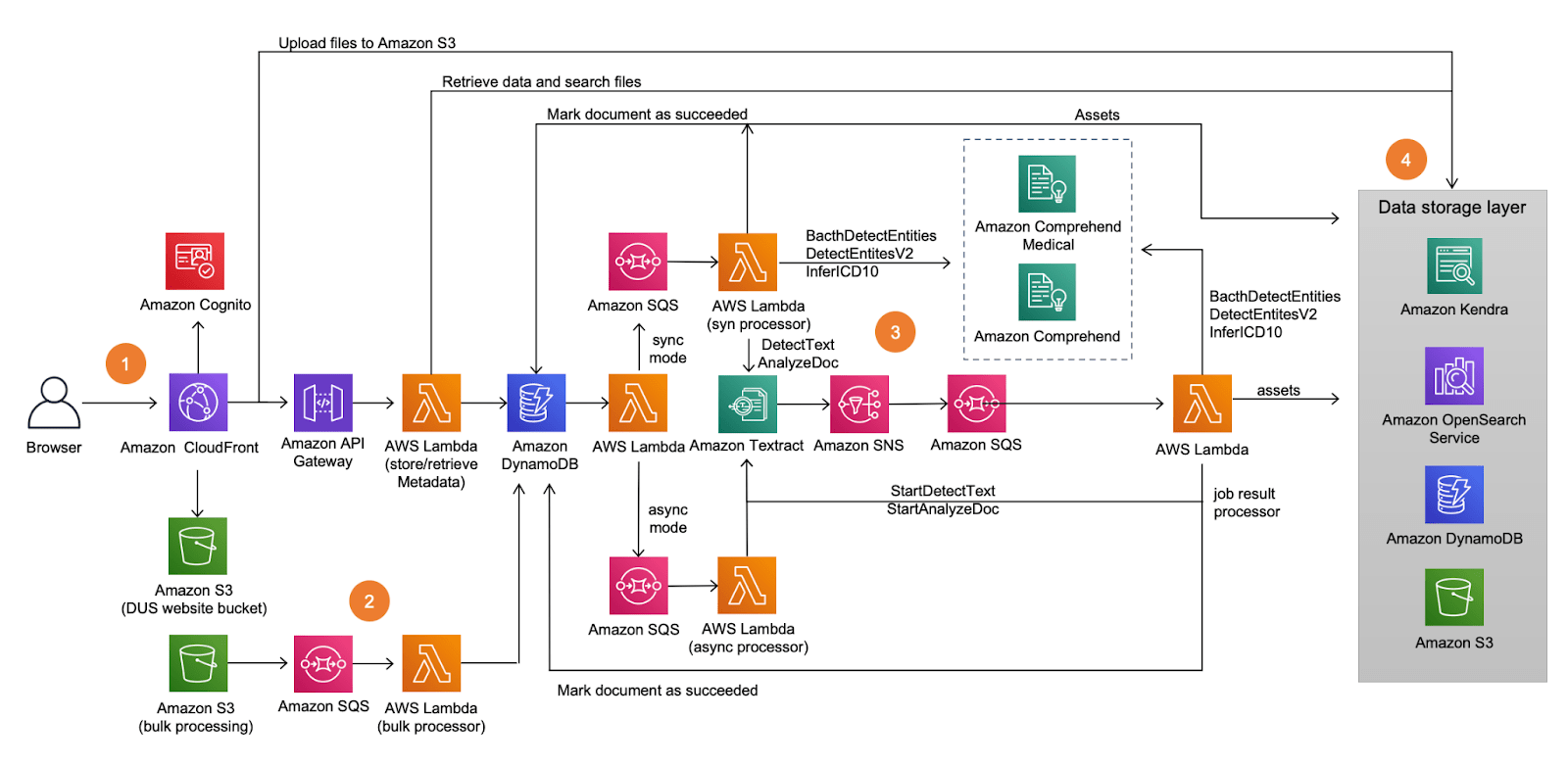
The AWS CloudFormation template deploys a static web application hosted on an Amazon S3 bucket and served by an Amazon CloudFront distribution. Users are authenticated using Amazon Cognito. The web application interacts with the backend using an Amazon API Gateway API, supported by an AWS Lambda function. The following are the steps to deploy the demo –
- Launch the following CloudFormation stack.
- On the parameters page configure as required and enter “Email”.
- Select Create stack to deploy the stack.
- After receiving a CREATE_COMPLETE status, verify that both the DUS and DUSClient stacks also display a CREATE_COMPLETE status.
Documents are uploaded using the web application, or directly to a dedicated Amazon S3 bucket for bulk processing. The API initiates document processing, which triggers a Lambda function to add an entry to an Amazon DynamoDB table. The table triggers a second Lambda function that supervises the processing. The file format of the upload dictates the route for processing. Amazon Textract extracts text and structural information from the files. The extracted text is then passed to Amazon Comprehend for further analysis.
Benefits
Businesses can access critical insights in real-time, saving significant time and resources that would’ve been required to manually search through massive data. The benefits include:
- 52% reduced errors, thereby improving decision-making
- Manual cost of processing documents reduced by 35%
- Over all time spent on document related tasks reduced by 17%
- Improve compliance and risk management
- Increase operational efficiencies
- Enhance business processes through automation