
Amazon Simple Storage Service, also known as Amazon S3, is an online storage facility. It is cheap, fast, and easy to set up. With Amazon, an e-commerce giant, providing the service, one can assure the security of the stored data.
Amazon S3 is one of the core services and among the pillars of the AWS cloud infrastructure. The S3 stands for “Simple Storage Service” and is among the three foundational services that Amazon started with back in 2006. Almost all services in the AWS cloud infrastructure use this service in one way or another. In simple terms, Amazon S3 is an object store just like a regular file system on the computer but is “infinitely scaling,” as AWS advertises it. S3 doesn’t impose a limit on the amount of data that can be stored.
The key features of the s3 service are – infinite, highly scalable, high availability, high durability, manageability, and security. Even with the option of infinite storage, in terms of cost, it is one of the most cost-effective services on a pay-as-you-use model. S3 can store all kinds of images, text, and multimedia data.
The article covers the following sections: Amazon S3 overview.
- S3 Buckets and Objects overview.
- S3 Advance features.
- S3 Popular use cases.

The introduction to AWS Services is a mini-series containing articles that provide a basic introduction to different AWS services. Each article covers a detailed guide on how to use the AWS Service. The series aims to provide “A Getting Started Guide on Different AWS Services.”
Amazon S3 overview
Amazon S3 allows users to build highly scalable applications with infinite but inexpensive storage. S3 being a fast, affordable, and reliable option enables it to be a backbone for many cloud-based applications. It is also an integral service in the AWS cloud infrastructure, with integration options available for most services. Users can store or retrieve any amount of data per their needs at any time from around the globe.
S3 stores all data as objects, making it suitable for various types of data, including text-based data like server logs and multimedia data like images, videos, or mp3 files. S3 ensures high reliability and data integrity with 99.99% availability, equivalent to just 53 minutes of downtime in a year, and 99.999999999% durability, meaning it loses a single object every 10,000 years.
Accessing the service is straightforward through the management console, offering users a well-designed and user-friendly interface to easily manage all the different features and options.
In addition to the console, the AWS CLI and SDKs for S3 are also available for more programmatic access.
Some more advanced features that S3 offers are object encryption for data security, versioning and replication for backup and durability, storage classes for cost optimization based on object access patterns, auditing, monitoring, and compliance features, permissions, and access management at the user, bucket, and even object level for restricted access, query in-place support for other AWS services to allow direct query on the objects.
S3 Buckets and Objects overview
A general overview of the S3 service reveals that it structures objects using the convention of buckets and objects.
Buckets
A bucket in S3 is just like a directory that contains an unlimited number of objects(files).
By default, AWS account holders can have up to 100 buckets (subject to a soft limit), but they can increase this limit by requesting additional buckets from AWS.
By not imposing a cap on the number of objects that users can store in a single bucket, S3 enables virtually unlimited scalability. However, each individual object uploaded to S3 can be a maximum of 5 terabytes (TB) in size.
S3 being a regional service means that it stores buckets at the regional level.
Each bucket has a globally unique name (bucket names follow a convention), meaning that only one bucket can have a given name at a time in the entire AWS infrastructure unless deleted by the bucket owner. Buckets are created in a specific region. So selecting geographically closer regions can help minimize latency.
Objects
An object in S3 is just a file that is stored. Objects consist of data and metadata. Each object has a unique key that consists of a prefix and the object name. E.g., s3://s3bucket/some_folder/s3_object.txt
The bucket name, key, version ID, and object name uniquely identify the object. Although mentioned earlier that buckets are like directories and even the UI on the management console will show a directory structure, there’s no concept of directories within buckets, nor do any directories exists like in a Linux file system.
The directories in buckets are only there for data organization purposes. S3 works entirely with keys. S3 objects can be 5TB in size but unlimited in number. Objects also have additional attributes like metadata, version, and tags.
Objects Consistency Model
Due to its high availability and durability, the S3 service ensures atomic updates to objects, guaranteeing that it never partially updates an object. The consistency model for S3 is based on two approaches:
Read after write consistency for new objects
When a new object is requested immediately after its creation, S3 might initially return a 404 error, indicating that the object is not found. However, the object eventually becomes available.
Eventual Consistency for objects overwrites
Immediately after an update, when retrieving an object, S3 might return either the old copy or the new one. However, it ensures that it never returns the object in a partially updated state.
Buckets, objects, and keys together make up the entire working structure of the S3 service.
Below are the advanced features for buckets and objects in S3:
S3 Advance features
Although it serves as a foundational service, it offers many advanced features, listed as follows:
Storage Classes and Life Cycle Management
The S3 service permits objects to transition into different storage classes based on their access patterns, thereby reducing storage costs. Users can manually perform this transition via the management console or configure lifecycle policies using the SDK, enabling objects to automatically transition into different storage classes based on predefined criteria.
Storage Classes
Users can select from a range of storage classes offered by S3 based on the access patterns of objects, aligning with popular use cases for S3.
S3 Standard:
This is the default storage class for all objects. This storage class well suits frequently accessed objects, such as images, and performance-sensitive use cases.
S3 Reduced Redundancy Storage(RRS):
This storage class also caters to frequently accessed objects but is more suitable for non-critical data that organizations can easily reproduce if lost. AWS recommends not using RRS.
S3 Intelligent-Tiering:
This storage class is suitable for use cases to optimize storage costs automatically. Depending upon the changes in object access patterns, the S3 Intelligent-Tiering moves data automatically to a frequent access tier or low-cost infrequent access tier. For this storage class, a small monthly automation and monitoring fee is associated with each object. No additional tiering fees or object retrieval fees are related to this storage class. Ideal for use cases having long-lived data with unknown and unpredictable access patterns.
S3 Standard-IA and S3 One Zone-IA:
These storage classes are suitable for long-lived, infrequently accessed objects such as backup files.
The difference between S3 Standard-IA and S3 One Zone-IA is that the former stores data across multiple availability zones redundantly while the latter stores data in only one AZ.
Hence One Zone-IA is less expensive but less resilient and available and prone to the physical loss of data compared to Standard-IA.
S3 Glacier and S3 Glacier Deep Archive:
These storage classes are suitable for archiving data and have the lowest cost of all the above storage classes. Data in Glacier and Deep Glacier Archive is not readily available, and data retrieval can take from 1 minute to 12 hours in the case of Glacier and about 12 hours in the case of Deep Glacier Archive. The following storage classes are suitable for data that rarely need to be accessed. AWS provides a detailed analysis of S3 storage classes:
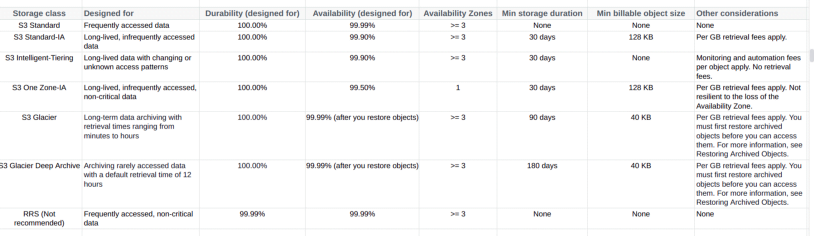
S3 Storage Classes Comparison
For more details on S3 storage and classes, visit the S3 documentation.
Life Cycle Management
S3 provides transitioning objects into different storage classes as per the need to reduce costs. Life cycle configuration(a set of rules) is applied to the objects. S3 performs the actions as in the configurations. Two types of actions are performed:
Transition actions
These actions transition objects from one storage class to another after a specified time interval, e.g., after seven days or 15 days, etc. Additional costs are associated with life cycle transition requests.
Expiration actions
These actions delete the objects after the specified interval.You can configure lifecycle management by directly setting it on a bucket via the management console or by providing an Excel document containing predefined actions (stored as an S3 sub-resource) to execute on objects via API operations
For more details on S3 life cycle management, visit the S3 documentation.
S3 Object Versioning
Another feature the S3 service provides is object versioning. At the bucket level, you enable versioning, and by default, you disable it for buckets. Once enabled, versioning assigns a unique version ID to each S3 object within the bucket. S3 assigns a null version ID for objects present before versioning was enabled. However, new objects uploaded after enabling versioning receive a unique version ID for each upload. These version IDs are auto-generated and noneditable.
S3 versioning allows for storing multiple versions of an object and prevents an object’s accidental deletions and overwrites. Users can also use it for archival purposes. The following images show the behavior of versioning for overwrites and delete:
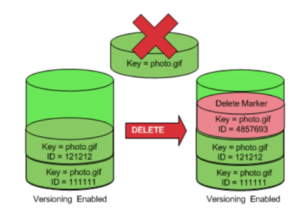
Every time a user updates an object in S3, S3 keeps the original version in the bucket. Instead of overwriting the existing object, S3 generates a new copy of the updated object with a new and unique version ID. Subsequently, S3 designates this new version as the current version of the object.
Similarly, when a user deletes an object in S3, S3 applies a delete marker to the object, indicating its deletion, while retaining the object itself in the bucket. Attempting to retrieve the deleted object results in a 404 error from S3.
To permanently delete an object, you must include the version ID in the deletion request. This action deletes the current version and sets the next most recent version as the current version.
S3 Replication
S3 replication enables the copying of objects from one bucket to another bucket within the same or a different AWS account, and also within the same or another region. To configure object replication, you provide a replication configuration to the source bucket, which includes at least the destination bucket and an IAM role for S3 to copy the objects.
For object replication, we have cross-region object replication (CRR) and same region object replication (SRR).
Aside from data redundancy purposes, S3 replication can serve various use cases, including:
Replication of objects with different storage classes. Object replication with different ownership.
S3 Replication Time Control (S3 RTC) to copy 99.99% of objects within the same or a different region in 15mins or less.
Some vital considerations include enabling object versioning for both source and destination buckets for replication. Configuring replication for the bucket does not automatically copy objects existing before the configuration, necessitating the need to contact AWS support for their replication.
S3 Security and Encryption
Security
S3 durability and reliability are one of its most attractive features providing 99.999999999% (eleven 9s)durability and 99.99% availability. AWS provides a highly secure and fault-tolerant infrastructure, replicating data in S3 across multiple availability zones to withstand the concurrent loss of data in two AZs.
S3 also provides user-based and resource-based security options to restrict access to specific users, buckets, and objects.
User-based restriction: IAM policies enable the definition of specific actions that a user can perform on S3.
Resource-based restriction: Resource-based actions can be on buckets or objects within buckets for even finer control. These are done via bucket policies and access control lists (ACLs). By default, S3 buckets are private, and we specifically allow public access to the bucket and objects via the bucket policies and ACLs, respectively.
Encryption
You can enhance the security of data in S3 by utilizing the encryption options provided within the service. Encryption can be either:
Server-Side: Unencrypted data is uploaded on S3 and encrypted first before physically stored by S3 and decrypted on access. The S3 service manages the keys used for encryption. S3 also provides options for the client to use its encryption keys in this case.
Client-Side: Data is encrypted at the client’s end and uploaded to S3 in encrypted form. The client is responsible for key management in this case.
S3 popular use cases
AWS S3 serves as a popular solution for various use cases such as data backups, data storage, and hybrid cloud storage. Media include images, music and videos, application hosting, and Static Website Hosting. Data archiving, Data Lakes building, and Data Analytics on Data Lakes, Disaster recovery.
Summary
The article summarizes the working model of S3 and the various features offered by the service. Many different applications can utilize S3 as a foundational service. The lucrative features provided in S3, along with its ability to store an infinite amount of data with high durability and accessibility at a low cost, make it one of the most go-to services for any architecture.
Article Credits: Adit Modi
Adit is a Cloud, DevOps & Big Data Evangelist | 4x AWS Certified | 3x OCI Certified | 3x Azure Certified | AWS Community Builder | AWS Educate Cloud Ambassador.