
Why Serverless Database?
Serverless databases, like Aurora Serverless, are gaining traction due to their ability to automatically adjust capacity based on real-time workloads. This eliminates the need for manual data processing and database resource management, leading to cost savings and streamlined operations. A key benefit of serverless databases is their inherent ability to seamlessly scale up or down in response to demand fluctuations.
In this article, we will explore the dynamic world of serverless databases, with a specific focus on Aurora Serverless. These databases have been gaining immense popularity for their unique ability to adapt capacity in real-time, reducing the need for manual resource management, data processing and significantly streamlining operations. We will delve into the advantages of serverless databases and help you understand when it makes sense to go completely serverless or opt for a mixed configuration to strike the right balance between cost efficiency and performance. So, let’s dive into the intricacies of serverless database deployment and discover the best strategies for your unique database needs.
When to go completely Serverless?
Different companies have unique usage patterns depending on their target audience and operational hours. A fully serverless approach might not be suitable for everyone. Serverless instances can be roughly 1.5 times more expensive than regular ones. Therefore, it’s often wise to allocate the baseline load to standalone instances. You can then leverage serverless resources only when scaling is truly necessary.
Application Scenario 1: For an application that needs to maintain a 15% baseline load throughout the day with occasional surges, a full serverless approach may not offer the most cost-effective solution.
Exhibit 1
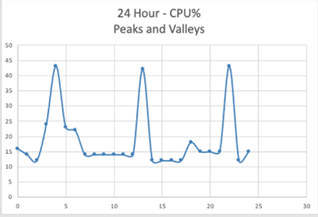
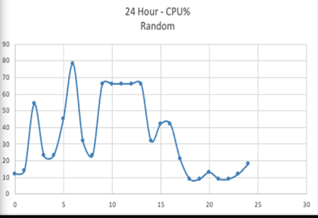
Application Scenario 2: On the other hand, for an application that experiences a fluctuating load that lacks a predictable pattern and requires varying resources throughout the day. In such cases, the serverless approach is often the most cost-effective choice.
Exhibit 2
The above two tables demonstrating ACU usage and cost in a serverless throughout the day for an application
Exhibit 3
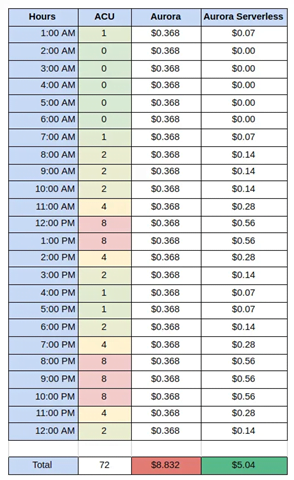
Exhibit 4
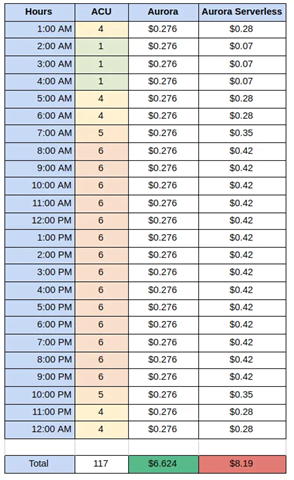
The above two tables demonstrating ACU usage and cost in a serverless and standalone instance-based database throughout the day
Exhibit 5
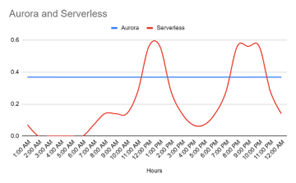
Exhibit 6
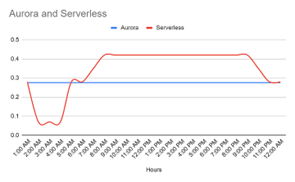
The above two figures demonstrating ACU usage in a serverless and standalone instance-based database throughout the day
Analyzing the cost data for Aurora Serverless and standalone instances as demonstrated by the two application scenarios above reveals divergent expense profiles. Application 1 incurs greater costs with Aurora, while application 2 Serverless is more cost-effective. These differences arise from the distinct usage patterns each application encounters. These stories underscore the notion that there is no universal, one-size-fits-all configuration for database deployment. Instead, the choice between Aurora Serverless and standalone instances demands a meticulous assessment to determine what aligns best with the specific needs and usage patterns of your application. In essence, it’s crucial to make a well-informed decision that caters to your unique requirements.
The Mixed Configuration
Suppose a food delivery company database experiences two usage peaks: one from 12 p.m. to 1 p.m. and another from 8 p.m. to 10 p.m. These are the time slots when the majority of your customers are actively using your application.
Exhibit7
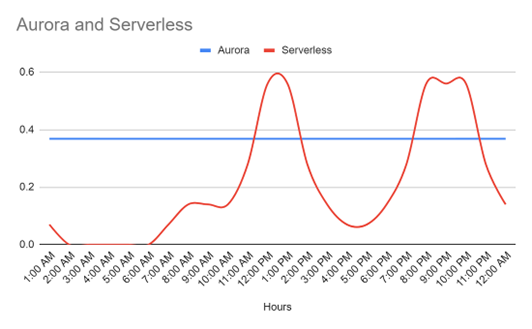
Exhibit 7: figure demonstrating ACU usage in a serverless and standalone instance-based database throughout the day
In this scenario, it’s prudent to handle the constant baseline load with more cost-effective standalone instances and utilize serverless instances exclusively when you require scaling.
How to build a Mixed Configuration
A mixed configuration RDS Database is basically a database where you create a DB that has both serverless instances and standalone working together.
First, create an RDS Instance
- Open the Amazon RDS console and select “Create Database.”
- On the page, choose either Aurora (MySQL Compatible) or Aurora (PostgreSQL Compatible) for the Engine type.
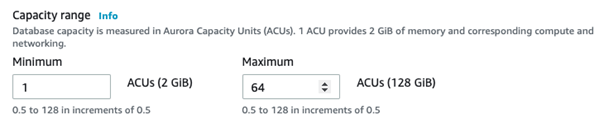
- In the Capacity settings, specify the minimum and maximum ACU based on your requirements.
- Create a database to set up your Aurora cluster with an Aurora Serverless v2 DB instance as the writer instance, also known as the primary DB instance.
- Then, on your database homepage, click on “Add reader.”
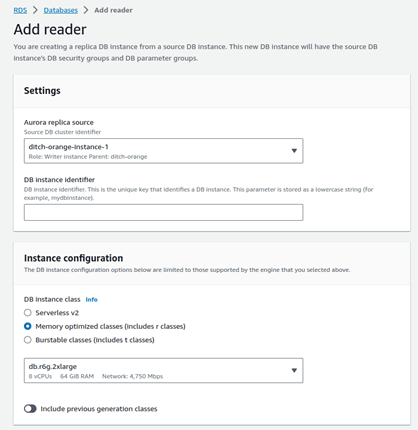
- Proceed to the Instance configuration tab, select “Memory optimized,” and click on “Add reader” at the bottom.
- By assigning a higher priority to the standalone instance, you will effectively route most of your traffic to the more cost-efficient instance.
- The serverless instance will be utilized to its maximum capacity only when necessary, ensuring maximum throughput.
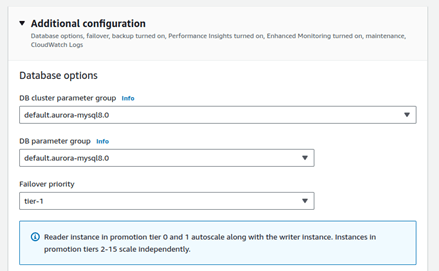
Additionally, this configuration aids in better load handling as the standalone instance manages the load while the serverless instances utilize resources during scaling out
Choosing the right parameters for your Database
Configuring ACU Limits for Aurora Serverless
Aurora Serverless offers the flexibility to set both minimum and maximum ACUs (Aurora Capacity Units) for your database, and making the right choices for these limits is vital to your database’s performance:
1. Assess Baseline and Peak Usage: Start by assessing your application’s typical workload and peak demands, including any addons and services, to determine the necessary baseline and maximum capacity. This information can be gathered by monitoring your existing RDS instance.
2. Performance Testing: Conduct performance testing to pinpoint the minimum capacity required to meet your performance expectations. This step ensures smooth application operation even during periods of low demand.
3. Scalability Considerations: Equally important is selecting the maximum ACUs. Evaluate your application’s scalability needs and opt for a maximum ACU limit that can comfortably handle peak traffic without incurring unnecessary cost overhead.
4. Real-time Adjustment: Continuously monitor your database’s performance through real-time metrics. Adapt the maximum ACUs as needed, factoring in the time required to optimize the database’s performance and leaving room to accommodate additional load when necessary.
Scaling Strategy
Vertical Scaling: Vertical scaling enhances database performance through resource allocation adjustments, either increasing or decreasing Aurora Capacity Units (ACUs).
Advantages:
Speed: Rapid implementation without the need for creating new instances.
Simplicity: Straightforward management of configuration settings.
Considerations:
Resource Limits: Scaling is limited to the capacity within the current serving regions.
Horizontal Scaling: Horizontal scaling involves adding read-only Aurora Replicas to your Aurora cluster to distribute read traffic across multiple instances.
Advantages:
High Availability: Enhances fault tolerance and availability.
Scalability: Enables easier expansion and scalability across multiple regions.
Considerations:
Latency: Potential introduction of additional latency due to data replication.
The decision between vertical and horizontal scaling hinges on your application’s needs, traffic behavior, and budget considerations. Vertical scaling offers a swift solution for adapting to predictable workloads and abrupt surges in traffic. Meanwhile, horizontal scaling proves cost-effective for handling steady read-heavy workloads and ensuring high availability. Opting for a hybrid approach can provide an optimal balance between performance and cost-efficiency for your Aurora Serverless database.
How to create an Autoscaling Policy?
On your RDS Database main page go to Logs & events and click Add
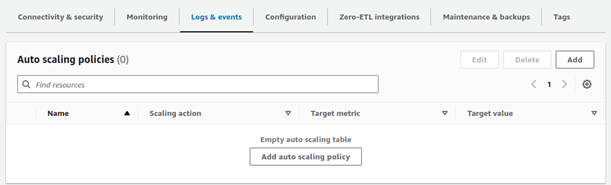
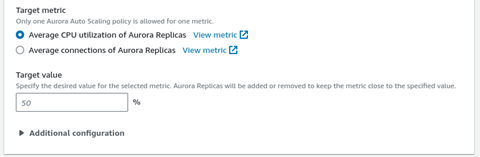
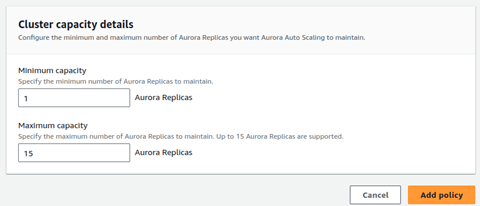
Finally click on Add policy and your policy will be ready to be used.
Auto-scaling operates through a policy that leverages metrics like average CPU utilization, the average number of database connections, and custom metrics to fine-tune the read capacity. When auto scaling is initiated, a fresh reader instance is introduced to the cluster. Conversely, when the target metric falls below the set threshold, the newly added instance is removed. It’s worth noting that this scaling-up process may entail a few minutes, as it involves launching a new reader database instance. If you are already using the auto-scaling feature, you have the option to consider replacing it with the vertical scaling provided by Aurora Serverless v2.
How to tune In-Database Hyperparameters
Connection Pooling: Modify the maximum allowable simultaneous connections to prevent resource depletion and enhance performance. Avoid excessive over-provisioning.
Caching Strategies: Employ the query cache and buffer pool to enhance the performance of read-intensive workloads. Configure cache sizes thoughtfully, taking available memory into account.
InnoDB Buffer Pool: Fine-tune the InnoDB buffer pool size to optimize storage and access performance while closely monitoring read and write requirements.
Log File Size: Adapt the transaction log size to align with the database’s write workload, preventing performance issues related to log space.
Disabling Metrics: Disabling constant metric flow over time conserves valuable resources, allowing you to extract more efficiency from your database.
How to build your optimal database in 4 steps
Step 1: Choose a configuration based on requirement
Begin by thoroughly assessing your application’s usage patterns, daily demands, and frequency of resource throttling. This evaluation will guide you in making a crucial decision: choosing between serverless, standalone, or a mixed RDS configuration, depending on your specific requirements.
Step 2: Look at your usage pattern to build scaling policies
Analyze your usage patterns in-depth to formulate effective scalability policies. Define the minimum and maximum load variations over time and establish the ideal Amazon Aurora Capacity Units (ACUs) requirements. This allows you to fine-tune your RDS scaling strategies for optimal performance.
Step 3: Selecting ideal parameters of your database
To ensure the efficiency of your database, consider the number of reader instances required to support your intended regional coverage. Determine the optimal configuration based on the geographic regions in which you want to serve your audience. Additionally, assess the fail-safe needs to guarantee reliable and responsive database performance.
Step 4: Fine-Tuning for Peak Performance
To further optimize your database’s performance, apply a range of adjustments:
• Prevent Resource Exhaustion with Connection Pooling
•Improve Read-Heavy Workloads with Caching Policies
•Balance Storage and Access Performance with InnoDB Optimization
• Log File Size Adjustment for Optimal Performance
•Fine-Tuning Analytics for Efficiency
Conclusion
The world of database deployment is not one-size-fits-all. As we’ve seen, the decision to go fully serverless or opt for a mixed configuration, horizontal vs vertical scaling depends on your specific usage patterns and needs. By carefully assessing your requirements, fine-tuning scalability policies, and selecting the right parameters, you can create an optimal database setup that delivers peak performance and cost-efficiency. Whether you choose the agility of serverless or the reliability of a mixed approach, making an informed decision is crucial in catering to your unique application demands. In the ever-evolving realm of database management, adaptability, and precision are key to ensuring your database seamlessly supports your growth and operational goals.