
A US-based telecommunication, networking, and software services company wanted to build a corporate research platform that provides faster and more comprehensive customer and competitor insights to drive sales and strategy. So, it can create business intelligence (BI) dashboards on top of it for decision-making. Data sources like SEC filings and investor presentations are some input data feeds that will power the research platform. Finally, it requires the output data to be published to Snowflake.
The Challenge
Handle Structured and Unstructured Data: SEC filings are structured formats such as XBRL and semi/unstructured formats – tables and free-form text.
Design for Flexibility, Simplicity, and Scale: Set up flexible infrastructure and data pipeline automation that can handle layers of complexity in the data processing.
Support Complexity and Custom Analytics: Allow analytics and aggregations at different stages of data processing and publish results to distribution channels such as Snowflake, Kafka, and S3 or last-mile tools such as Excel and Dashboards.
Why Data and Analytics on AWS?
Leverage AWS to deliver services that provide virtually everything needed to quickly and easily build and manage data analytics solutions. These secure and easy to use managed services enable customers to deploy virtually any big data application on AWS.
The Solution
Built a solution that automates the provisioning of data lake infrastructure resources and deploys ETL jobs interactively. Data Stack is automated with AWS CDK and Step functions workflows. Results are published to client Snowflake Data Share, from which they had lot of options for data crunching and visualization.
Extracting facts from the XBRL documents:
XBRL, which stands for eXtensible Business Reporting Language, is an XML based language for tagging financial data and enabling businesses to efficiently and accurately process and share their data. XBRL instances contain the information that is being exchanged. That information is expressed in the form of facts. Each fact is associated with a concept from an XBRL taxonomy, which expresses the concept and defines it.
- The XBRL Specification explains what XBRL is, and how to build XBRL instance documents and XBRL taxonomies.
- The XBRL Schema is the physical XSD file that expresses how instance documents and taxonomies are to be built.
- The XBRL Linkbases are the physical XML files that contain various information about the elements defined in the XBRL Schema.
- An XBRL Taxonomy is a “vocabulary” or “dictionary” created by a group, compliant with the XBRL Specification, to exchange business information.
- An XBRL Instance document is a business report, such as a financial statement prepared to the XBRL specification.
Understanding and processing XBRL filings has few moving parts and is a bit involved when it comes to extracting insights for analysis, audit or investment research purposes.
Data Lake Infrastructure
The data lake infrastructure provisioning includes Amazon S3 buckets, S3 bucket policies, AWS Key Management Service (KMS) encryption keys, Amazon Virtual Private Cloud (Amazon VPC), subnets, route tables, security groups, VPC endpoints, and secrets in AWS Secrets Manager.
Data Lake ETL Jobs
In ETL jobs, the SEC filings are processed to produce the output. The following figure displays ETL process that involves four ETL jobs within a Step Functions state machine.
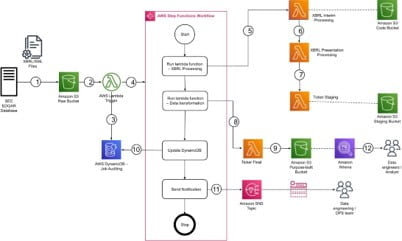
- XBRL downloader API uploads files to the S3 raw bucket of the data lake. The file server is a data producer and source for the data lake. It is assumed that the data is pushed to the raw bucket.
- Amazon S3 triggers an event notification to the Lambda function.
- The function inserts an item in the Amazon DynamoDB table in order to track the file processing state. The first state written indicates the AWS Step Function start.
- The function starts the state machine.
- The state machine runs AWS Lambda functions
- The job stores the result in JSON format in the purpose-built zone.
- The job updates the DynamoDB table and updates the jpb status to completed.
- An Amazon Simple Notification Service (Amazon SNS) notification is sent to subscribers that states the job is complete.
- Data engineers or analysts can now analyze data via Snowflake
Centralized Deployment
Deployment model is based on the following design principles:
A dedicated AWS account to run CDK pipelines.
One or more AWS accounts into which the data lake is deployed.
The data lake infrastructure has a dedicated source code repository. Typically, data lake infrastructure is a one-time deployment and but can evolve over time. Therefore, a dedicated code repository provides a landing zone for your data lake.
Each ETL job has a dedicated source code repository. Each ETL job may have unique AWS service, orchestration, and configuration requirements. Therefore, a dedicated source code repository will help you more flexibly build, deploy, and maintain ETL jobs.
Distribution via Integration Touch Points – Snowflake
With Secure Data Sharing, no actual data is copied or transferred between accounts. All sharing is accomplished through Snowflake’s unique services layer and metadata store.
- Client created a share of a database in their account and granted access to specific objects in the database.
- On the consumer side, a read-only database is created from the share. Access to this database is configurable using the same, standard role-based access control that Snowflake provides for all objects in the system.
- New objects added to a share become immediately available to all consumers, providing real-time access to shared data.
Transformed data is stored in Amazon S3 to be used for ingestion to Snowflake.
Results and Benefits
Digital Alpha helped the client consume raw XBRL and non-XBRL data from customers’ and competitors’ SEC reports, making critical business decisions and bolstering competitive insights.
The proprietary automated solution helped them convert structured and unstructured data to a readable and machine-processable JSON format, eventually publishing results to Snowflake data share. They utilized a fully automated solution to perform various analytics, run quant models, and conduct slicing and dicing of available data.
Finally, they established a data pipeline that removed human intervention, eliminated manual errors, and achieved deployment at speed and scale.
The following list encompasses some advantages:
- Generate insights from public filings by leveraging our AWS ETL Pipeline
- Automated processing of financial data in complex format to extract valuable insights
- Automate set up of the entire tech stack and the ETL jobs with AWS CDK
- Publish results to different systems such as Kafka, Snowflake, AWS S3 buckets
- Solution is generic and scalable for application on any type of dataset
- Enables real time processing of SEC filings within seconds
- Utilize CI/CD pipeline and best practices for shipping features quickly
- Achieve a competitive edge by harnessing streaming data and analytics to enable critical business decision
The flexibility of Digital Alpha’s solution has also provided much greater speed and agility, opening up the possibility of real-time competitive intelligence monitoring for the client.
To sum up, Digital Alpha expands the utility of data for the investment management industry through AWS and Snowflake. Client team was able to gain valuable insights into their customers and competitors.