
Introduction
In recent years, Large Language Models (LLMs) have revolutionized the field of artificial intelligence, demonstrating remarkable capabilities in various tasks. However, these models face limitations in terms of up-to-date knowledge and domain-specific expertise. This is where Retrieval-Augmented Generation (RAG) and other techniques for integrating external data come into play. This article explores the findings of a comprehensive survey on RAG and related methods, highlighting their importance, challenges, and future directions.
The Importance of External Data in LLMs
Large Language Models (LLMs) are powerful tools in the realm of artificial intelligence, yet they possess several inherent limitations that can hinder their effectiveness:
- Knowledge Cutoff: LLMs are trained on data up to a specific point in time, which restricts their ability to access the most recent information. This limitation can lead to outdated responses, particularly in fast-evolving fields such as technology, finance, and healthcare.
- Domain Specificity: General-purpose LLMs often lack in-depth knowledge in specialized fields. While they can generate coherent text on a wide range of topics, they may struggle with complex queries that require expert-level understanding or nuanced insights.
- Hallucination: LLMs can sometimes produce false or inconsistent information, a phenomenon known as “hallucination.” This occurs when the model generates content that is not grounded in its training data or real-world facts, leading to potential misinformation.
Integrating external data through techniques like Retrieval-Augmented Generation (RAG) addresses these issues by:
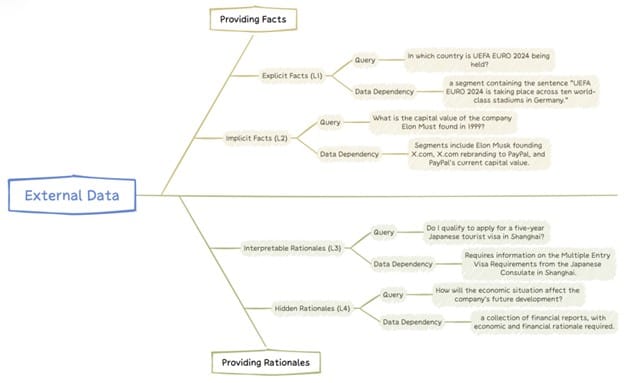
- Enhancing Domain-Specific Expertise: By connecting LLMs to specialized databases and real-time information sources, RAG allows models to access up-to-date knowledge that is crucial for generating accurate responses. For instance, if a user queries about the latest advancements in renewable energy technologies, RAG can retrieve relevant articles and studies to inform the model’s output.
- Improving Temporal Relevance of Information: RAG enables LLMs to bypass their static knowledge base by dynamically retrieving current information. This ensures that the responses generated are not only accurate but also timely, significantly improving the relevance of the information provided.
- Reducing Instances of Hallucination: The integration of reliable external sources helps mitigate hallucination by grounding the model’s outputs in factual data. When LLMs can reference authoritative documents or databases, the likelihood of generating misleading or incorrect information decreases.
- Increasing Controllability and Interpretability of Outputs: Incorporating external data allows for greater control over the outputs generated by LLMs. Users can specify the type of information they want the model to consider, enhancing interpretability and ensuring that responses align more closely with user intent.
Understanding Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is an innovative methodology that enhances the capabilities of large language models (LLMs) by integrating them with robust information retrieval systems. This approach addresses the limitations of LLMs, particularly their reliance on pre-existing knowledge without real-time data access. The RAG process typically involves three key steps:
Data Index Construction
The first stage in RAG is the construction of an index from various data sources. This index serves as a structured repository where information can be efficiently stored and retrieved. The data can come from diverse formats, including relational databases, unstructured documents, and even live data feeds. By transforming this information into a format suitable for quick access, RAG systems ensure that relevant data can be fetched promptly when needed.
Retrieval System Construction
Once the data index is established, the next step involves creating a retrieval system. This system is responsible for processing user queries and fetching relevant documents or data snippets from the index. The retrieval process typically utilizes advanced algorithms that analyze the semantic meaning of the user’s input, allowing the system to identify and retrieve the most pertinent information. This step is crucial, as the quality of the retrieved data directly impacts the accuracy and relevance of the final output generated by the LLM.
Answer Generation
After relevant information has been retrieved, it is integrated with the original user query to enhance context and detail. This augmented prompt is then processed by the LLM, which generates a coherent and contextually rich response. The incorporation of external data not only improves factual accuracy but also allows for responses that are more tailored to specific user needs, making RAG particularly effective in applications requiring up-to-date information or domain-specific expertise.
Key Components of RAG
- Document Processing: Parsing and chunking of source documents, including multi-modal content.
- Indexing: Creating mappings from search terms to text segments using sparse, dense, or hybrid retrieval methods.
- Query Processing: Reformulating and expanding queries to improve retrieval accuracy.
- Retrieval and Matching: Fetching relevant information based on the processed query.
- Re-ranking and Correction: Filtering and reordering retrieved text segments.
- Response Generation: Combining retrieved information with the LLM’s knowledge to generate coherent answers.
Challenges and Solutions in RAG Implementation
Retrieval-Augmented Generation (RAG) systems present unique challenges that can hinder their effectiveness. Understanding these obstacles and their potential solutions is crucial for successful implementation. Below are the primary challenges segmented into three categories: Data Processing, Retrieval, and Generation.
1. Data Processing Challenges
- Multi-modal Document Parsing: Extracting coherent information from various formats—text, tables, and figures—can be complex. Effective parsing requires advanced techniques that can handle diverse data types while maintaining the integrity of the information.
- Chunking Optimization: Balancing semantic coherence with information completeness during text segmentation is essential. Overlapping chunks can provide necessary context while ensuring that critical information is not lost, thus enhancing retrieval accuracy.
2. Retrieval Challenges
- Query-Document Mismatch: Differences in terminology between user queries and document content can lead to ineffective retrieval. Implementing query expansion techniques can help bridge this gap by reformulating user queries to include synonyms or related terms, thereby improving match rates.
- Retrieval Accuracy: Improving the relevance of retrieved information is paramount. Techniques such as re-ranking retrieved documents using cross-encoders can enhance accuracy by considering complex interactions between queries and documents, ensuring that the most relevant results are prioritized.
3. Generation Challenges
- Handling Irrelevant or Erroneous Information: Developing robust methods to filter out noise and incorrect data is critical. This includes cleaning source data to remove duplicates and irrelevant entries, which can significantly improve the quality of outputs generated by RAG systems.
- Balancing Retrieved Knowledge and Model Prior: Conflicts between external data and a large language model’s (LLM) internal knowledge can arise. Implementing mechanisms that allow the model to weigh external information against its training data helps resolve these conflicts, ensuring that generated responses are both accurate and contextually appropriate.
Advanced RAG Techniques
1. Iterative RAG
Iterative RAG employs multi-step processes to refine the retrieval of information, ensuring that the most accurate and relevant answers are achieved. This technique is particularly useful in complex scenarios where a single retrieval may not suffice. Key approaches include:
- Planning-based methods: These involve strategic frameworks that outline the steps needed to gather and verify information dynamically, enhancing the overall reliability of the output.
- Self-reflection and correction techniques: By incorporating mechanisms that allow the system to evaluate its previous outputs, these techniques enable ongoing adjustments and refinements, leading to improved accuracy over time.
- Multi-Hop Retrieval: This advanced method iteratively retrieves information from multiple sources, enhancing context and depth in responses. It allows for a recursive approach where each step builds upon the last, refining the relevance and accuracy of the information retrieved.
2. Structured RAG
Structured RAG leverages organized data representations to bolster both retrieval and reasoning capabilities. This structured approach enhances the model’s ability to access and interpret data effectively. Notable methods include:
- Knowledge Graph-based methods: These utilize interconnected data points to provide a richer context for retrieval, enabling more nuanced understanding and generation.
- Data Chunk Graphs/Trees: By breaking down information into manageable chunks organized hierarchically, these methods facilitate efficient retrieval while maintaining contextual integrity.
- Hybrid Search Models: Combining traditional keyword search with semantic search techniques, this approach ensures that a wide variety of query types can be effectively addressed, improving overall retrieval performance.
3. RAG with Structured Data
This technique integrates Retrieval-Augmented Generation with structured data sources such as databases, enhancing the model’s ability to generate accurate responses grounded in reliable information. Key strategies include:
- Text-to-SQL techniques: These methods convert natural language queries into SQL queries, enabling direct access to structured data within databases. This integration allows for precise data retrieval necessary for informed response generation.
- Hybrid approaches: By combining natural language processing with structured data queries, these methods enhance the model’s capability to retrieve relevant information from diverse sources, ensuring comprehensive responses that are contextually rich and accurate.
- Continuous Monitoring and Refinement: Implementing a feedback loop where the system is regularly evaluated against real-world performance can lead to ongoing improvements in how structured data is utilized within RAG systems.
Beyond RAG: Other Data Integration Techniques
In the ever-evolving landscape of artificial intelligence, particularly in the realm of large language models (LLMs). Various data integration techniques play crucial roles in enhancing model performance and adaptability. While Retrieval-Augmented Generation (RAG) is a prominent method. Several other techniques are equally significant in optimizing the use of data for AI applications.
Fine-tuning
Fine-tuning involves adapting LLMs to specific domains or tasks by conducting additional training on relevant datasets. This process allows models to leverage existing knowledge while honing in on particular areas, improving their effectiveness in specialized applications. Fine-tuning is particularly useful when the target task requires nuanced understanding or domain-specific knowledge that is not sufficiently covered during initial training.
In-Context Learning
In-context learning (ICL) is a powerful technique that enables LLMs to learn new tasks using natural language prompts without explicit retraining. By providing examples or instructions within the input prompt, ICL guides the model’s behavior and responses. This method allows for flexibility in task adaptation, as models can generalize from a few input-output examples or even a single example, making it a highly efficient approach for various applications.
Key aspects of ICL include
- Few-shot learning: Utilizing multiple input-output pairs to help the model understand task requirements.
- Zero-shot and one-shot learning: Adapting to tasks with no or minimal examples provided.
ICL has shown significant promise across diverse sectors, including sentiment analysis and customer service, where it can quickly adapt to user queries and provide contextually relevant responses without extensive retraining.
Parameter-Efficient Fine-Tuning
Parameter-efficient fine-tuning (PEFT) represents an innovative approach to enhancing the performance of LLMs while minimizing resource requirements. Unlike traditional fine-tuning methods that may involve extensive computational resources, PEFT focuses on adjusting only a small subset of model parameters. This method retains the integrity of the pre-trained model while allowing for effective customization for specific tasks.
Benefits of PEFT include:
1. Reduced computational costs: By only modifying essential parameters, PEFT significantly lowers the energy and time required for adaptation.
2. Faster time-to-value: Organizations can deploy models more rapidly for new use cases without undergoing full retraining processes.
3. Preservation of generalization capabilities: This approach prevents catastrophic forgetting, ensuring that valuable pre-trained knowledge remains intact.
PEFT techniques such as adapters, prefix tuning, and low-rank adaptation make it easier for teams to customize models efficiently, democratizing access to advanced AI capabilities across various industries.
Each of these techniques—fine-tuning, in-context learning, and parameter-efficient fine-tuning. It Offers unique advantages and plays a vital role in the broader context of data integration for AI applications. As organizations continue to explore innovative ways to leverage AI technologies, understanding and implementing these methods will be essential for maximizing performance and adaptability.
Future Directions and Challenges
Improving Retrieval Efficiency
Enhancing the efficiency of retrieval methods is a critical area of focus. Researchers are exploring advanced algorithms that can reduce computational overhead while increasing accuracy. This involves refining existing models and integrating machine learning techniques to optimize search processes. Ultimately aiming for faster response times and more relevant results. Innovations in hardware, such as specialized processing chips, may also play a role in achieving these goals.
Enhancing Multi-modal Capabilities
The integration of various data types—text, images, audio, and video—is essential for creating more comprehensive retrieval systems. Future developments should focus on seamless multi-modal capabilities that allow users to query across different formats effortlessly. This requires improved representation techniques that can effectively combine and analyze diverse data sources. Ensuring that retrieval systems can deliver holistic responses to user queries.
Addressing Ethical Concerns
As data-augmented large language models (LLMs) become more prevalent, ethical considerations surrounding privacy, fairness, and transparency must be prioritized. Ensuring that these systems do not perpetuate biases or violate user privacy is paramount. Researchers are tasked with developing frameworks that promote ethical standards in the design and implementation of retrieval systems, fostering trust among users and stakeholders.
Scalability
With the exponential growth of external knowledge bases, scalability presents a significant challenge for retrieval systems. Effective strategies must be developed to manage the integration of vast amounts of information without compromising performance. Techniques such as distributed computing and cloud-based solutions are potential avenues for addressing these scalability issues, allowing retrieval systems to handle larger datasets efficiently.
Evaluation Metrics
The establishment of robust evaluation metrics is crucial for assessing the performance of retrieval-augmented generation (RAG) systems. Current evaluation paradigms often fall short in capturing the nuances of user satisfaction and system effectiveness. Future research should aim to develop comprehensive benchmarks that consider both the efficiency and effectiveness of retrieval processes. Facilitating a more accurate assessment of system performance in real-world applications.
These future directions not only highlight the potential advancements in information retrieval. However, also underscore the challenges that need to be addressed to ensure these technologies serve users effectively and ethically.
Conclusion
Retrieval-Augmented Generation and related techniques represent a significant advancement in enhancing the capabilities of Large Language Models. By effectively integrating external data, these methods address many of the limitations of traditional LLMs. Paving the way for more accurate, up-to-date, and domain-specific AI applications. As research in this field continues to evolve. We can expect even more sophisticated and powerful AI systems that can seamlessly combine vast language understanding with dynamic, real-world knowledge.
Know more in the research paper ‘Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely’