
Retrieval-Augmented Generation (RAG) has transformed the way machines process and generate information. Now, a new player in the field, Graph RAG, is causing a revolution in this domain by combining the power of knowledge graphs and graph databases with RAG techniques. This innovative approach enhances semantic search capabilities and improves the accuracy and relevance of generated content, opening up new possibilities for AI-driven applications.
Graph RAG leverages graph structures and embeddings to create a more nuanced understanding of information relationships. By integrating entity extraction and graph-based RAG methods, it offers significant advantages over traditional vector search techniques. This article will explore the concept of Graph RAG, its benefits, and how to implement it. We’ll also look at its applications in various fields and how it’s shaping the future of knowledge graph construction and utilization in AI systems.
Understanding Graph RAG
What is Graph RAG?
Graph RAG is an innovative approach that enhances traditional Retrieval-Augmented Generation (RAG) by integrating knowledge graphs and graph databases. This method aims to address the limitations of conventional RAG systems by providing a more comprehensive and contextually rich information retrieval process . Graph RAG leverages the power of knowledge graphs to capture the semantic structure of data, enabling more accurate and relevant responses to user queries .
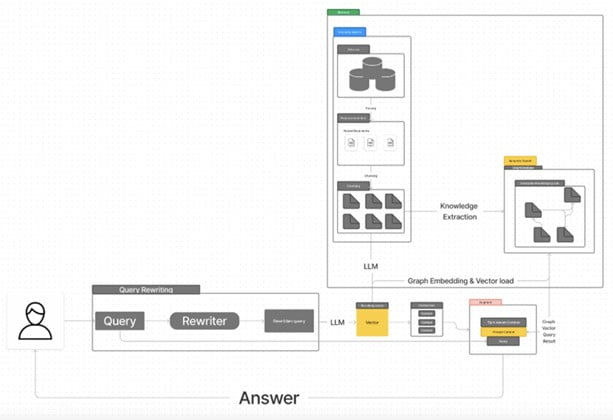
Image credits: Jeong Yitae
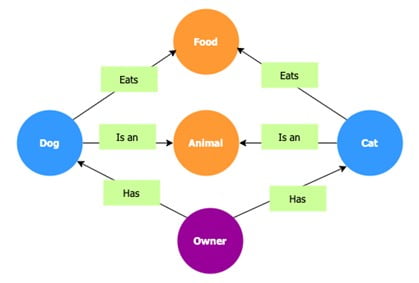
At its core, Graph RAG uses knowledge graphs instead of vector databases for information retrieval, resulting in more wholesome and meaningful outputs compared to baseline RAG . This approach allows for a broader and more holistic view of data, integrating diverse knowledge through graph structures . By doing so, Graph RAG expands the horizon of information retrieval, enabling AI systems to see the bigger picture and provide more insightful solutions.
Key components of Graph RAG
Graph RAG typically consists of several key components that work together to enhance the retrieval and generation process:
- Knowledge Graph Construction: A comprehensive knowledge graph is created by extracting entities and relationships from available data sources. This process involves entity recognition, relationship extraction, and knowledge fusion to build a unified representation of the information.
- Document Indexing: Documents are processed and indexed using techniques like embedding-based search to facilitate efficient retrieval.
- Query Processing: User queries are analyzed to identify relevant entities and their relationships within the knowledge graph.
- Knowledge Graph Query: The system queries the knowledge graph to retrieve entities and relationships that are relevant to the user’s query.
- Contextual Enrichment: Information retrieved from both the document index and the knowledge graph is combined to create a comprehensive context for the Language Model (LLM) .
- Response Generation: The LLM generates a response based on the provided context, leveraging the structured information from the knowledge graph to improve coherence and accuracy.
How Graph RAG differs from traditional RAG

Graph RAG introduces several key differences that set it apart from traditional RAG approaches:
- Knowledge Representation: While traditional RAG relies primarily on vector databases, Graph RAG utilizes knowledge graphs to represent information. This allows for a more structured and semantically rich representation of data.
- Contextual Understanding: Graph RAG provides a broader context by capturing relationships between entities. This enables the system to understand and utilize the interconnections within the data, leading to more comprehensive and accurate responses.
- Semantic Search: By leveraging graph structures, Graph RAG enhances semantic search capabilities. This allows for more nuanced information retrieval based on the relationships and properties of entities, rather than relying solely on keyword matching or vector similarity.
- Global Query Handling: The community structure within knowledge graphs enables Graph RAG to answer global queries that would be challenging for traditional RAG approaches. This feature provides users with overviews of datasets at different levels, offering a better understanding of the overall context.
- Explainability and Traceability: Graph RAG offers improved explainability by providing structured entity information, including descriptions, properties, and relationships. This makes it easier to trace the origins of information and understand how conclusions are drawn.
- Efficiency: In some cases, Graph RAG can be more efficient than summarizing full texts while still generating high-quality responses. This is particularly useful when dealing with large datasets or complex information structures.
- Flexibility and Integration: Graph RAG allows for easier integration of diverse knowledge sources and domains. This flexibility makes it particularly useful for connecting different datasets or independent sources of information.
By leveraging these unique features, Graph RAG offers a more sophisticated and context-aware approach to information retrieval and generation. It addresses many of the limitations of traditional RAG systems, providing a foundation for more accurate, comprehensive, and insightful AI-driven applications.
Benefits of Graph RAG
Graph RAG offers significant advantages over traditional Retrieval-Augmented Generation systems, enhancing the capabilities of AI applications across various domains. By leveraging the power of knowledge graphs and graph databases, this innovative approach addresses many limitations of conventional RAG systems, providing more comprehensive and contextually rich information retrieval and generation processes.
Enhanced contextual understanding
Graph RAG significantly improves the contextual understanding of information by utilizing knowledge graphs to capture the semantic structure of data. This approach allows AI systems to comprehend the relationships and attributes of entities within the graph, leading to a more profound understanding of the subject matter. By representing information as a network of interconnected nodes and relationships, Graph RAG enables AI systems to navigate efficiently from one piece of information to another, accessing all related data.
This enhanced understanding of relationships has several benefits:
- Improved handling of complex queries: Graph RAG excels at addressing intricate and ambiguous queries by leveraging the rich semantic structure of the knowledge graph.
- Efficient information retrieval: The connected data structure allows RAG applications to traverse and navigate through interconnected documents more easily, enabling multi-hop reasoning to answer complex questions.
- Holistic view of data: Graph RAG provides a broader and more comprehensive perspective on information by integrating diverse knowledge through graph structures.
Improved accuracy and relevance
Graph RAG significantly enhances the accuracy and relevance of responses generated by AI systems. This improvement is evident in several key areas:
- Factual grounding: By utilizing external data sources, Graph RAG systems offer responses that are more precise and grounded in factual information compared to those generated by independent language models.
- Adaptability to changing information: Graph RAG’s structure enables it to effectively handle topics that are constantly evolving, ensuring that the generated responses remain up-to-date and relevant.
- Reduced hallucinations: Extensive experiments on graph multi-hop reasoning benchmarks have demonstrated that Graph RAG approaches significantly outperform current state-of-the-art RAG methods while effectively mitigating hallucinations.
The improved accuracy of Graph RAG has been validated by recent benchmarks. Data.world reported that Graph RAG, on average, improved the accuracy of LLM responses by 3x across 43 business questions . Additionally, Microsoft discovered that Graph RAG required between 26% and 97% fewer tokens than alternative approaches, indicating improved efficiency .
Multi-hop reasoning capabilities
One of the most significant advantages of Graph RAG is its ability to perform multi-hop reasoning, allowing AI systems to draw connections and inferences across multiple related pieces of information. This capability is particularly valuable for addressing complex queries that require deep understanding and logical reasoning.
Key aspects of multi-hop reasoning in Graph RAG include:
- Path exploration: Graph RAG can identify and traverse paths between entities, enabling it to answer questions that require multiple steps of reasoning. For example, it can address queries such as “What are the common genes associated with DiseaseX and DiseaseY” by exploring the connections between diseases and genes .
- Complex relationship analysis: Graph RAG excels at uncovering mechanistic relationships between entities. For instance, it can elucidate the connection between a compound and a disease by traversing multiple intermediate steps, such as reactions, enzymes, proteins, and genes .
- Efficient query processing: By breaking down complex queries into sub-queries, Graph RAG can facilitate more comprehensive and accurate information retrieval. The knowledge graph assists in identifying relevant sub-topics and guiding the query planning process .
The multi-hop reasoning capabilities of Graph RAG have practical applications in various fields. For example, LinkedIn used Graph RAG to reduce their ticket resolution time from 40 hours to 15 hours . This significant improvement demonstrates the power of Graph RAG in handling complex, interconnected information efficiently.
In conclusion, Graph RAG’s benefits of enhanced contextual understanding, improved accuracy and relevance, and multi-hop reasoning capabilities make it a powerful tool for advancing AI applications across diverse domains. As the field continues to evolve, Graph RAG is poised to play a crucial role in developing more sophisticated and context-aware AI systems.
Implementing Graph RAG
Building the knowledge graph
To implement Graph RAG effectively, the first step is to construct a high-quality knowledge graph from unstructured documents. This process involves several interconnected stages designed to extract, refine, and structure information efficiently . The construction of a knowledge graph typically comprises knowledge acquisition, refinement, and evolution steps .
One approach to creating knowledge graphs is using Grapher, which employs a multi-stage process. Initially, an LLM extracts entities from the text, followed by generating relationships between these entities . Another method is PiVe (Prompting with Iterative Verification), which relies on iterative verification to continuously improve the performance of an LLM. A smaller language model acts as a verification module, checking the output of the LLM and optimizing it step by step using fine-grained correction instructions.
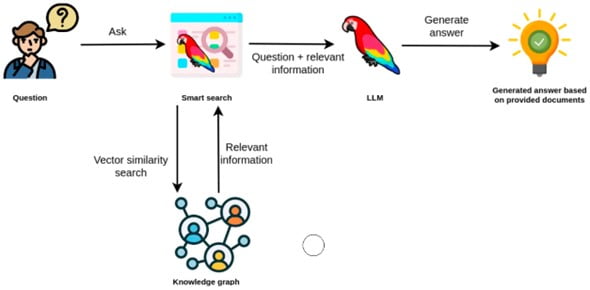
Image credits: LangChain
To build a knowledge graph using LangChain & Neo4j, developers can follow these steps:
- Set Up Neo4j: Install Neo4j (version 5.11 or greater) either locally or on the cloud (e.g., Neo4j Aura).
- Create Knowledge Graph: Define nodes (e.g., microservices, tasks) and relationships in your knowledge graph to represent entities and their connections.
- Import Data: Populate the knowledge graph with data from various sources like cloud services and task management tools.
- Calculate Embeddings: Use LangChain to calculate text embeddings for tasks and store them as properties in the graph.
- Build Vector Index: Create a vector index within Neo4j to perform similarity searches on task descriptions.
- Perform Vector Search: Use the vector index to retrieve relevant tasks based on user queries.
- Implement Cypher Queries: Use Cypher queries to aggregate and analyze structured data within the graph.
- Combine Tools in LangChain: Integrate the vector index and Cypher queries into a LangChain agent to handle both structured and unstructured queries.
- Deploy and Test: Use the LangChain agent to run various queries and refine the system as needed.
Integrating with existing RAG systems
Integrating Graph RAG with existing RAG systems involves leveraging the structured knowledge representation of knowledge graphs to enhance the performance of natural language processing tasks. This integration allows for more accurate and context-aware generation of responses based on the structured information extracted from documents .
To integrate Graph RAG with existing systems, developers can follow these steps:
- Load and preprocess text data from which the knowledge graph will be extracted.
- Initialize a language model and use it to extract a knowledge graph from the text chunks.
- Store the knowledge graph in a persistent and queryable format, such as Neo4j .
- Set up components for retrieving relevant knowledge from the graph based on user queries.
- Generate responses using the retrieved context.
The GraphCypherQAChain from LangChain can be used to query the graph database using natural language queries, making it easier to extract information from the graph.
Best practices for Graph RAG deployment
When deploying Graph RAG systems, several best practices should be considered to ensure optimal performance and efficiency:
- Chunking strategy: Experiment with various chunk sizes to find the optimal balance. Larger chunk sizes can be beneficial, but the benefits may taper off after a certain point.
- Overlap in chunking: Implement intentional duplication of tokens at the boundaries of adjacent chunks to ensure context preservation when passing chunks to the LLM for generation.
- Embedding model selection: Choose an appropriate embedding model, as it can significantly impact the performance of RAG systems .
- Retrieval algorithms: Implement efficient and precise retrieval algorithms. Consider using both term-based matching (like BM25) and vector similarity search methods.
- LLM selection: Choose the right LLM based on the application’s objectives. Modern LLMs excel in reasoning and critical evaluation of acquired knowledge.
- Hybrid routing: Consider employing multiple LLMs with a supervisor model to guide input queries to the most appropriate LLM.
- Intent classification: Combine RAG with intent classifiers to optimize the approach between a naive RAG application and a complex conversational agent.
By following these best practices and leveraging the power of knowledge graphs, developers can create robust and efficient Graph RAG systems that provide more accurate, contextually rich, and insightful responses to user queries.
Conclusion
Graph RAG is causing a revolution in the field of Retrieval-Augmented Generation by combining knowledge graphs with traditional RAG techniques. This innovative approach has a significant impact on semantic search capabilities and enhances the accuracy and relevance of generated content. By leveraging graph structures and embeddings, Graph RAG offers a more nuanced understanding of information relationships, opening up new possibilities for AI-driven applications across various domains.
As the technology continues to evolve, Graph RAG is set to play a crucial role in shaping the future of knowledge graph construction and use in AI systems. Its ability to handle complex queries, perform multi-hop reasoning, and provide more contextually rich responses makes it a powerful tool to enhance AI applications. Moving forward, the ongoing development and refinement of Graph RAG techniques will likely lead to even more groundbreaking advancements in the field of artificial intelligence and information retrieval.