In this blog we will run multi-node training jobs using AWS Trainium accelerators in Amazon EKS. Specifically, you will pretrain Llama-2-7b on 4 AWS EC2 trn1.32xlarge instances using a subset of the RedPajama dataset.
Choosing the appropriate model size of Llama-2 depends on your specific requirements. The largest model might not always be necessary for optimal performance. It’s crucial to consider factors like computational resources, response times, and cost efficiency. Make an informed decision by assessing the needs and limitations of your application thoroughly.
Performance Boost
While Llama-2 can achieve high-performance inference on GPUs, Neuron accelerators take performance to the next level. Neuron accelerators are purpose-built for machine learning workloads, providing hardware acceleration that significantly enhances Llama-2’s inference speeds. This translates to faster response times and improved user experiences when deploying Llama-2 on Trn1 instances.
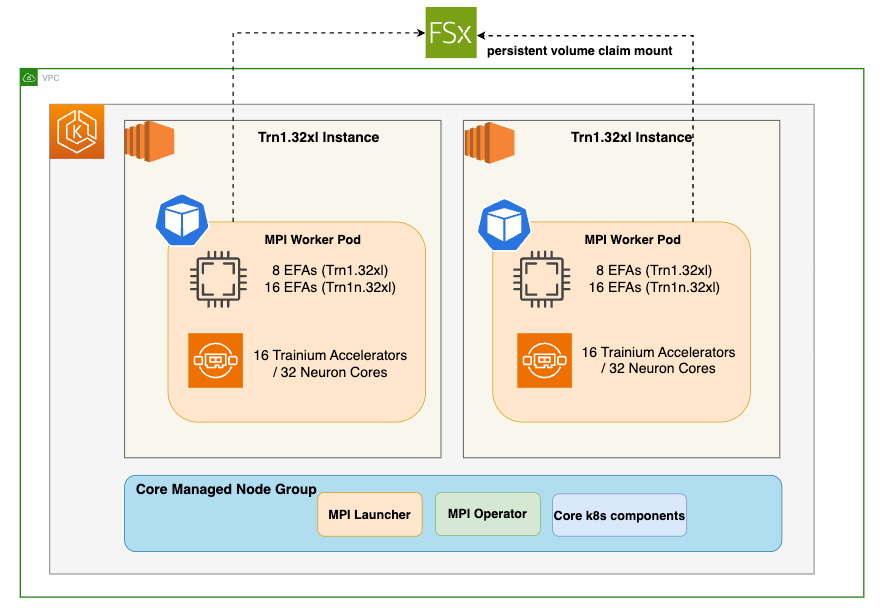
Before we begin, ensure you have all the prerequisites in place to make the deployment process smooth and hassle-free.
Ensure that you have installed the following tools on your EC2.
Clone the Data on EKS repository
git clone https://github.com/awslabs/data-on-eks.git
cd data-on-eks/ai-ml/trainium-inferentia
By default MPI operator is not installed and its set to false. We will run the below export commands to set environment variables.
export TF_VAR_enable_mpi_operator=true
export TF_VAR_enable_fsx_for_lustre=true
export TF_VAR_region=us-west-2
export TF_VAR_trn1_32xl_min_size=4
export TF_VAR_trn1_32xl_desired_size=4
Run the install script to provision an EKS cluster with all the add-ons needed for the solution.
./install.sh
aws eks --region us-west-2 describe-cluster --name trainium-inferentia
# Creates k8s config file to authenticate with EKS
aws eks --region us-west-2 update-kubeconfig --name trainium-inferentia
kubectl get nodes # Output shows the EKS Managed Node group nodes
cd examples/llama2/
1-llama2-neuronx-pretrain-build-image.sh script to build the neuronx-nemo-megatron container image and push the image into ECR.
When prompted for a region, enter the region in which you launched your EKS cluster, above.
./1-llama2-neuronx-pretrain-build-image.sh
./2-launch-cmd-shell-pod.sh
kubectl get pod -w
kubectl exec -it cli-cmd-shell -- /bin/bash
huggingface-cli login command to login to Hugging Face using your access token. The access token is found under Settings → Access Tokens on the Hugging Face website.
huggingface-cli login
ENTER.
Next, you download the llama7-7b tokenizer files to /shared/llama7b_tokenizer by running the following python code:
python3 <<EOF
import transformers
tok = transformers.AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
tok.save_pretrained("/shared/llama7b_tokenizer")
EOF
cd /shared
git clone https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T-Sample \
data/RedPajama-Data-1T-Sample
cd /shared
# Clone the neuronx-nemo-megatron repo, which includes the required scripts
git clone https://github.com/aws-neuron/neuronx-nemo-megatron.git
# Combine the separate redpajama files to a single jsonl file
cat /shared/data/RedPajama-Data-1T-Sample/*.jsonl > /shared/redpajama_sample.jsonl
# Run preprocessing script using llama tokenizer
python3 neuronx-nemo-megatron/nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py \
--input=/shared/redpajama_sample.jsonl \
--json-keys=text \
--tokenizer-library=huggingface \
--tokenizer-type=/shared/llama7b_tokenizer \
--dataset-impl=mmap \
--output-prefix=/shared/data/redpajama_sample \
--append-eod \
--need-pad-id \
--workers=32
/shared/neuronx-nemo-megatron/nemo/examples/nlp/language_modeling/test_llama.sh to update the following two lines. These lines tell the training pod workers where to find the Llama tokenizer and the dataset on the FSx filesystem.
Run:
sed -i 's#^\(: ${TOKENIZER_PATH=\).*#\1/shared/llama7b_tokenizer}#' /shared/neuronx-nemo-megatron/nemo/examples/nlp/language_modeling/test_llama.sh
sed -i 's#^\(: ${DATASET_PATH=\).*#\1/shared/data/redpajama_sample_text_document}#' /shared/neuronx-nemo-megatron/nemo/examples/nlp/language_modeling/test_llama.sh
: ${TOKENIZER_PATH=$HOME/llamav2_weights/7b-hf}
: ${DATASET_PATH=$HOME/examples_datasets/llama_7b/book.jsonl-processed_text_document}
: ${TOKENIZER_PATH=/shared/llama7b_tokenizer}
: ${DATASET_PATH=/shared/data/redpajama_sample_text_document}
CTRL-X, then y, then ENTER.
When you are finished, type exit or press CTRL-d to exit the CLI pod.
If you no longer need the CLI pod you can remove it by running:
kubectl delete pod cli-cmd-shell
kubectl get all -n mpi-operator
./3-llama2-neuronx-mpi-compile.sh
kubectl get pods | grep compile and wait until you see that the compile job shows ‘Completed’.
When pre-compilation is complete, you can then launch the pre-training job on 4 trn1.32xl nodes by running the following script:
./4-llama2-neuronx-mpi-train.sh
kubectl get pods | grep launcher
kubectl get pod test-mpi-train-launcher-xxx -o json | jq -r ".metadata.uid"
UID in the following command with the above value.
kubectl exec -it test-mpi-train-worker-0 -- tail -f /shared/nemo_experiments/UID/0/log
CTRL-C to quit the tail command.
kubectl exec -it test-mpi-train-worker-0 -- /bin/bash -l neuron-top
./5-deploy-tensorboard.sh
kubectl delete mpijob test-mpi-train
kubectl get pods to confirm that the launcher/worker pods have been removed.
cd data-on-eks/ai-ml/trainium-inferentia
./cleanup.sh
Ready to connect your technology stack?
AI-powered transformation for private equity portfolio companies and financial services firms. Built on AWS with enterprise-grade security.
© 2026 Digital Alpha Platform· 100 Overlook Center, Princeton, NJ 08540
Ready to connect your technology stack?
AI-powered transformation for private equity portfolio companies and financial services firms. Built on AWS with enterprise-grade security.
© 2026 Digital Alpha Platform· 100 Overlook Center, Princeton, NJ 08540